
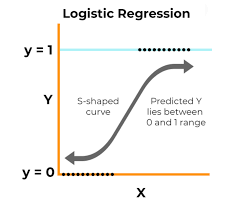
机器学习之回归
Logistic回归Logistic回归是一种用于二分类问题的统计学习方法。它通过对输入特征的线性组合结果应用Sigmoid函数,将输出映射到0和1之间,从而预测某个事件发生的概率。与线性回归不同,逻辑回归的输出是概率值,常用于分类任务。 基础概念Sigmoid函数Sigmoid函数是一种常用的激活函数,定义为: $$\sigma(z) = \frac{1}{1 + e^{-z}}$$ 它的输出范围在0到1之间,适合用于概率预测。 单位阶跃函数与Sigmoid函数在二分类问题中,我们希望模型能够根据输入预测类别(0或1)。理想情况下,可以使用单位阶跃函数(Heaviside step function)来实现: $$f(x) = \begin{cases}1, & x \geq 0 \0, & x <...
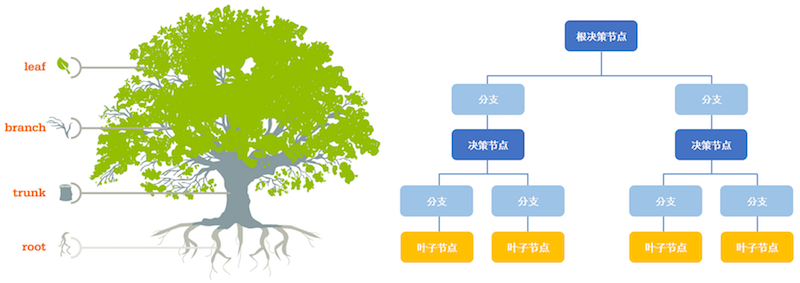
机器学习之决策树详解:从原理到实践
引言决策树(Decision Tree)是机器学习中最基础且最实用的算法之一,广泛应用于分类和回归问题。它以其直观的树形结构、易于理解和解释的特点,成为数据挖掘和机器学习领域的经典算法。 什么是决策树?决策树是一种树形结构的预测模型,通过一系列的问题(特征判断)来对数据进行分类或预测。每个内部节点代表一个特征测试,每个分支代表测试的一个可能结果,每个叶节点代表一个预测结果。 决策树的基本结构12345根节点 (Root Node) → 特征判断 ├── 分支1 → 内部节点 → 特征判断 │ ├── 分支1.1 → 叶节点 (预测结果1) │ └── 分支1.2 → 叶节点 (预测结果2) └── 分支2 → 叶节点 (预测结果3) 核心概念详解1. 信息熵 (Information Entropy)信息熵是衡量数据集不确定性的重要指标,由香农(Shannon)提出。 定义: 对于数据集D,其熵定义为: 1H(D) = -Σ(pi *...
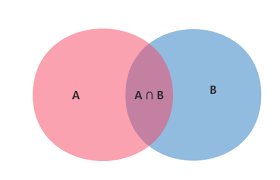
机器学习之朴素贝叶斯详解
目录 朴素贝叶斯概述 数学基础 朴素贝叶斯分类器 实际应用 优缺点分析 总结 朴素贝叶斯概述朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的概率分类算法,属于监督学习中的生成模型。它以其简单、高效和在某些场景下的优秀表现而闻名。 核心思想朴素贝叶斯的核心假设是特征条件独立性,即假设所有特征之间相互独立。虽然这个假设在现实中往往不成立,但正是这种”朴素”的假设使得算法计算简单且效果良好。 分类原理利用贝叶斯公式根据特征的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该特征所属的类: $$P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)}$$ 其中: $P(C|X)$ 是后验概率 $P(X|C)$ 是似然概率 $P(C)$ 是先验概率 $P(X)$ 是证据因子 数学基础条件概率条件概率是指在事件B发生的情况下,事件A发生的概率,记作 $P(A|B)$: $$P(A|B) = \frac{P(A \cap B)}{P(B)}$$ 全概率公式如果事件 $A_1, A_2, …, A_n$...
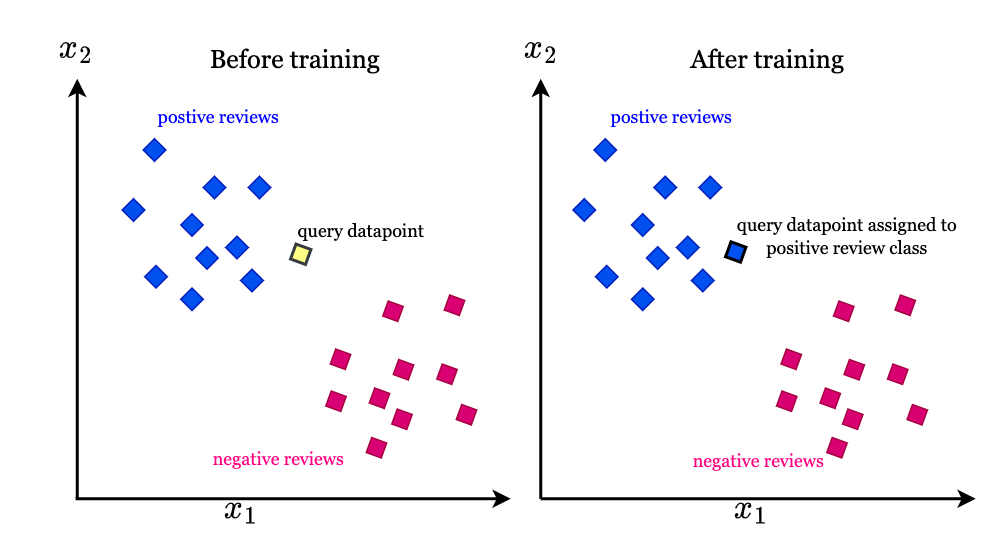
机器学习之KNN算法详解
什么是K-近邻算法?K-近邻(K-Nearest Neighbor, KNN)是一种监督学习算法,属于基于实例的学习或懒惰学习方法。它的核心思想是:物以类聚,即相似的对象应该属于同一类别。 算法基本概念 输入:样本的特征向量(在特征空间中的点) 输出:样本的类别标签 核心假设:相似的样本具有相似的标签 KNN算法原理详解1. 训练阶段KNN算法实际上没有显式的训练过程,它只是将训练数据存储起来,因此被称为”懒惰学习”。 2. 预测阶段当需要对新样本进行分类时,算法执行以下步骤: 距离计算:计算新样本与所有训练样本之间的距离 排序:将所有距离按从小到大排序 投票:选择前K个最近邻的类别标签 决策:通过多数投票确定新样本的类别 距离度量方法欧几里得距离(Euclidean Distance)最常用的距离度量方法,适用于连续型特征: $$d(x, y) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2}$$ 曼哈顿距离(Manhattan Distance)适用于离散型特征或城市街区距离: $$d(x, y) =...

机器学习
(注:博客属个人复习笔记,不会介绍基础概念,仅记录个人遗忘的部分知识点) RUNOBB教程 BLOG教程 机器学习 概述 “机器学习是对能通过经验自动改进的计算机算法的研究” “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准” 机器学习和深度学习的最大区别在神经网络,深度学习使用神经网络去提取事物的深层或者说是隐性的一些特征 常见的模型指标 正确率 —— 提取出的正确信息条数 / 提取出的信息条数 召回率 —— 提取出的正确信息条数 / 样本中的信息条数 F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值) 特征工程 (Feature Engineering)特征工程是机器学习项目中最关键的环节,直接影响模型性能。好的特征工程可以显著提升模型效果。 特征工程概述 定义:从原始数据中提取、转换、选择对模型有用的特征 重要性:数据和特征决定了机器学习的上限,模型和算法只是逼近这个上限 目标:提高模型性能、降低计算复杂度、增强模型可解释性 特征选择 (Feature...
Python并发编程
简介 引入并发,就是为了提升程序运行速度 单线程串行:不加改造的程序 多线程并发:threading 多线程:thhreadding,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴地等待IO完成 多cpu并行:multiprocessing 多进程:multiprocessing,利用CPU的多核原理,让CPU可以同时运行多个进程 多机器并行:hadoop/hive/spark IO:读取内存、磁盘、网络 异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行 使用Lock对资源加锁,防止冲突访问 使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式 使用线程池Pool/进程池Pool,实现线程/进程的任务提交、等待结束、获取结果 使用subprocess启动外部程序的进程,并进行输入输出的交互 怎样选择多线程、多进程和多协程 Thread Process...
大模型学习之DeepSeek
个人学习笔记,如有错误欢迎指正 参考链接🔗: B站视频 DeepSeek LLM: Scaling Open-Source Language Models with Longtermism DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 引言因为要看DeepSeek的优化的部分,绕不开的就是MoE 再然后就是COT MoE 混合专家模型混合专家模型详解 MoE发展历史Jacobs et al 1991 每个专家都是独立的FFN,Gating是FFN,由Gating来决定输出那一个专家的结果 2017...
FastApi
写的不全!参考视频 @fastapi框架FastApi: 一个用于构建API的现代、快速(高性能)的web框架 Starlette:一个用于构建ASGI(异步服务器网关接口)的web框架Pydantic:一个用于数据验证和序列化的库 1 预备知识点1.1 http协议1.1.1 简介HTTP协议是Hyper Text Transfer Protocol的缩写,它是一个用于在Internet上传输超文本的协议。HTTP是一个属于应用层的面向对象的协议。由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断的完善和拓展。HTTP工作与客户段-服务端架构上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据收到的请求后,向客户端发送响应信息。 1.1.2...
大模型学习之资源占用
待测试更新 大模型学习之资源占用资源:在本文中主要指的是cpu内存和gpu显存。 首先要分两种场景模型推理和模型训练进行讨论,针对不同的场景显存所需要加载的内容也不一样 0.预备知识模型参数1B 代表10亿个参数;1byte(字节)=8bit(位) 参数精度 fp32 fp16/bp16 int8/fp8 Int4 所占内存 4byte 2byte 1byte 0.5byte eg:fp32 1B:4byte * 10亿 / 1024^3(kb mb gb) 约等于 3.725GB 量化量化一般指的降低参数所占的内存空间,比如一个参数本来占4字节32位,现在为了节省空间,需要将其量化到int8也就是只允许参数占8位,量化的过程并不是简单的抹除小数位! 在神经网络模型导出的时候我们才会去做量化,以提高模型的推理速度以及模型所占显存大小,但量化同时会导致模型精度的下降。 量化方法的分类: QAT(Quant-Aware Training)也可以称为在线量化(On...
LlamaFactory参数详解
LlamaFactory参数详解Link LlamaFactory是一个简单易上手的大模型训练工具 微调的概念微调是指在一个已经预训练的模型基础上进行进一步的训练。预训练模型通常是在大规模数据集(如imageNet或大型文本语料库)上训练的,因此已经捕获了丰富的特征和知识。微调的目标是利用预训练模型的知识,在较小的数据集砂锅进行特定任务的优化。 主要特点1.预训练模型:基于已经训练好的模型进行 2.较少数据:通常只需要较小的数据集 3.较短时间:训练时间相对较短,因为模型已经有了良好的初始化 4.目标:适应特定任务或领域,优化模型性能 1.微调方法LORALoRA(低秩微调,Low-Rank Adaption)是一种通过低秩近似方法来减少模型参数数量和计算量的技术。它的主要目标是通过将原始的高纬参数矩阵分解成两个低秩矩阵的乘积(W ≈ A · B),从而实现模型的参数压缩和计算加速。 其中: W 是原始的高维参数矩阵。 A 和 B 是低秩矩阵,其秩(rank)远小于 W 的维度。 A的维度为 m x r 。 B的维度为 r x n 。 通过这种分解,我们可以将参数数量从 m...


