
机器学习之KNN算法详解
什么是K-近邻算法?
K-近邻(K-Nearest Neighbor, KNN)是一种监督学习算法,属于基于实例的学习或懒惰学习方法。它的核心思想是:物以类聚,即相似的对象应该属于同一类别。
算法基本概念
- 输入:样本的特征向量(在特征空间中的点)
- 输出:样本的类别标签
- 核心假设:相似的样本具有相似的标签
KNN算法原理详解
1. 训练阶段
KNN算法实际上没有显式的训练过程,它只是将训练数据存储起来,因此被称为”懒惰学习”。
2. 预测阶段
当需要对新样本进行分类时,算法执行以下步骤:
- 距离计算:计算新样本与所有训练样本之间的距离
- 排序:将所有距离按从小到大排序
- 投票:选择前K个最近邻的类别标签
- 决策:通过多数投票确定新样本的类别
距离度量方法
欧几里得距离(Euclidean Distance)
最常用的距离度量方法,适用于连续型特征:
$$d(x, y) = \sqrt{\sum_{i=1}^{n}(x_i - y_i)^2}$$
曼哈顿距离(Manhattan Distance)
适用于离散型特征或城市街区距离:
$$d(x, y) = \sum_{i=1}^{n}|x_i - y_i|$$
闵可夫斯基距离(Minkowski Distance)
欧几里得距离和曼哈顿距离的推广:
$$d(x, y) = (\sum_{i=1}^{n}|x_i - y_i|^p)^{\frac{1}{p}}$$
- 当 p=1 时,为曼哈顿距离
- 当 p=2 时,为欧几里得距离
余弦相似度(Cosine Similarity)
适用于文本分类等高维稀疏数据:
$$\cos(\theta) = \frac{x \cdot y}{||x|| \cdot ||y||}$$
KNN算法特点
优点
- ✅ 简单易懂:算法逻辑直观,易于理解和实现
- ✅ 无需训练:不需要显式的训练过程
- ✅ 对异常值不敏感:基于局部信息,受异常值影响较小
- ✅ 适用于多分类:天然支持多分类问题
- ✅ 理论成熟:有完善的理论基础
缺点
- ❌ 计算复杂度高:预测时需要计算与所有训练样本的距离
- ❌ 空间复杂度高:需要存储所有训练数据
- ❌ 对特征尺度敏感:不同特征的尺度差异会影响距离计算
- ❌ 维度灾难:在高维空间中,距离度量变得不可靠
- ❌ 需要大量内存:存储所有训练样本
如何选择最优的K值?
K值选择的影响
K值过小:
- 近似误差小(对训练数据拟合好)
- 估计误差大(容易过拟合,对噪声敏感)
K值过大:
- 近似误差大(对训练数据拟合差)
- 估计误差小(泛化能力强,但可能欠拟合)
选择策略
- 交叉验证法:使用k折交叉验证测试不同的K值
- 经验法则:K值通常选择为训练样本数的平方根
- 奇数值:对于二分类问题,选择奇数K值避免平票
- 领域知识:结合具体应用场景和领域经验
算法实现方式
1. 暴力搜索(Brute Force)
1 | def knn_brute_force(X_train, y_train, X_test, k): |
2. KD树(KD Tree)
使用二叉树根据数据维度来分割参数空间,适用于低维数据:
1 | from sklearn.neighbors import KDTree |
3. 球树(Ball Tree)
使用超球体来分割训练数据集,适用于高维数据:
1 | from sklearn.neighbors import BallTree |
实际应用场景
1. 图像分类
- 手写数字识别
- 人脸识别
- 图像内容分类
2. 推荐系统
- 基于用户的协同过滤
- 商品推荐
- 音乐推荐
3. 文本分类
- 垃圾邮件检测
- 情感分析
- 文档分类
4. 医学诊断
- 疾病预测
- 药物反应预测
- 基因表达分析
代码实现示例
Python实现
1 | import numpy as np |
参数调优
1 | from sklearn.model_selection import GridSearchCV |
性能优化技巧
1. 特征标准化
1 | from sklearn.preprocessing import StandardScaler, MinMaxScaler |
2. 特征选择
1 | from sklearn.feature_selection import SelectKBest, f_classif |
3. 降维处理
1 | from sklearn.decomposition import PCA |
总结
KNN算法是一种经典且实用的机器学习算法,具有以下特点:
- 简单有效:算法逻辑直观,易于理解和实现
- 适用广泛:可用于分类、回归等多种任务
- 理论基础扎实:有完善的理论支撑
- 实际应用丰富:在多个领域都有成功应用
虽然KNN算法存在计算复杂度高等缺点,但通过合理的数据预处理、特征工程和算法优化,仍然可以在实际项目中发挥重要作用。对于小到中等规模的数据集,KNN算法往往能够提供令人满意的性能。
进一步学习建议
- 学习其他距离度量方法
- 了解KNN的变体算法(如加权KNN)
- 探索KNN在深度学习中的应用
- 实践大规模数据的KNN优化技术
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 廾匸!
相关推荐
2025-06-10
机器学习之决策树详解:从原理到实践
引言决策树(Decision Tree)是机器学习中最基础且最实用的算法之一,广泛应用于分类和回归问题。它以其直观的树形结构、易于理解和解释的特点,成为数据挖掘和机器学习领域的经典算法。 什么是决策树?决策树是一种树形结构的预测模型,通过一系列的问题(特征判断)来对数据进行分类或预测。每个内部节点代表一个特征测试,每个分支代表测试的一个可能结果,每个叶节点代表一个预测结果。 决策树的基本结构12345根节点 (Root Node) → 特征判断 ├── 分支1 → 内部节点 → 特征判断 │ ├── 分支1.1 → 叶节点 (预测结果1) │ └── 分支1.2 → 叶节点 (预测结果2) └── 分支2 → 叶节点 (预测结果3) 核心概念详解1. 信息熵 (Information Entropy)信息熵是衡量数据集不确定性的重要指标,由香农(Shannon)提出。 定义: 对于数据集D,其熵定义为: 1H(D) = -Σ(pi *...
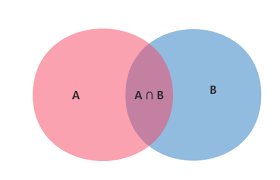
2025-06-10
机器学习之朴素贝叶斯详解
目录 朴素贝叶斯概述 数学基础 朴素贝叶斯分类器 实际应用 优缺点分析 总结 朴素贝叶斯概述朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的概率分类算法,属于监督学习中的生成模型。它以其简单、高效和在某些场景下的优秀表现而闻名。 核心思想朴素贝叶斯的核心假设是特征条件独立性,即假设所有特征之间相互独立。虽然这个假设在现实中往往不成立,但正是这种”朴素”的假设使得算法计算简单且效果良好。 分类原理利用贝叶斯公式根据特征的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该特征所属的类: $$P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)}$$ 其中: $P(C|X)$ 是后验概率 $P(X|C)$ 是似然概率 $P(C)$ 是先验概率 $P(X)$ 是证据因子 数学基础条件概率条件概率是指在事件B发生的情况下,事件A发生的概率,记作 $P(A|B)$: $$P(A|B) = \frac{P(A \cap B)}{P(B)}$$ 全概率公式如果事件 $A_1, A_2, …, A_n$...
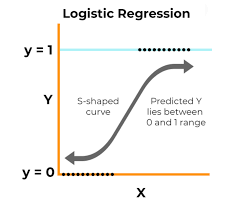
2025-06-11
机器学习之回归
Logistic回归Logistic回归是一种用于二分类问题的统计学习方法。它通过对输入特征的线性组合结果应用Sigmoid函数,将输出映射到0和1之间,从而预测某个事件发生的概率。与线性回归不同,逻辑回归的输出是概率值,常用于分类任务。 基础概念Sigmoid函数Sigmoid函数是一种常用的激活函数,定义为: $$\sigma(z) = \frac{1}{1 + e^{-z}}$$ 它的输出范围在0到1之间,适合用于概率预测。 单位阶跃函数与Sigmoid函数在二分类问题中,我们希望模型能够根据输入预测类别(0或1)。理想情况下,可以使用单位阶跃函数(Heaviside step function)来实现: $$f(x) = \begin{cases}1, & x \geq 0 \0, & x <...


