
大模型学习之DeepSeek
个人学习笔记,如有错误欢迎指正
参考链接🔗:
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
引言
因为要看DeepSeek的优化的部分,绕不开的就是MoE
再然后就是COT

MoE 混合专家模型
MoE发展历史
Jacobs et al 1991 每个专家都是独立的FFN,Gating是FFN,由Gating来决定输出那一个专家的结果
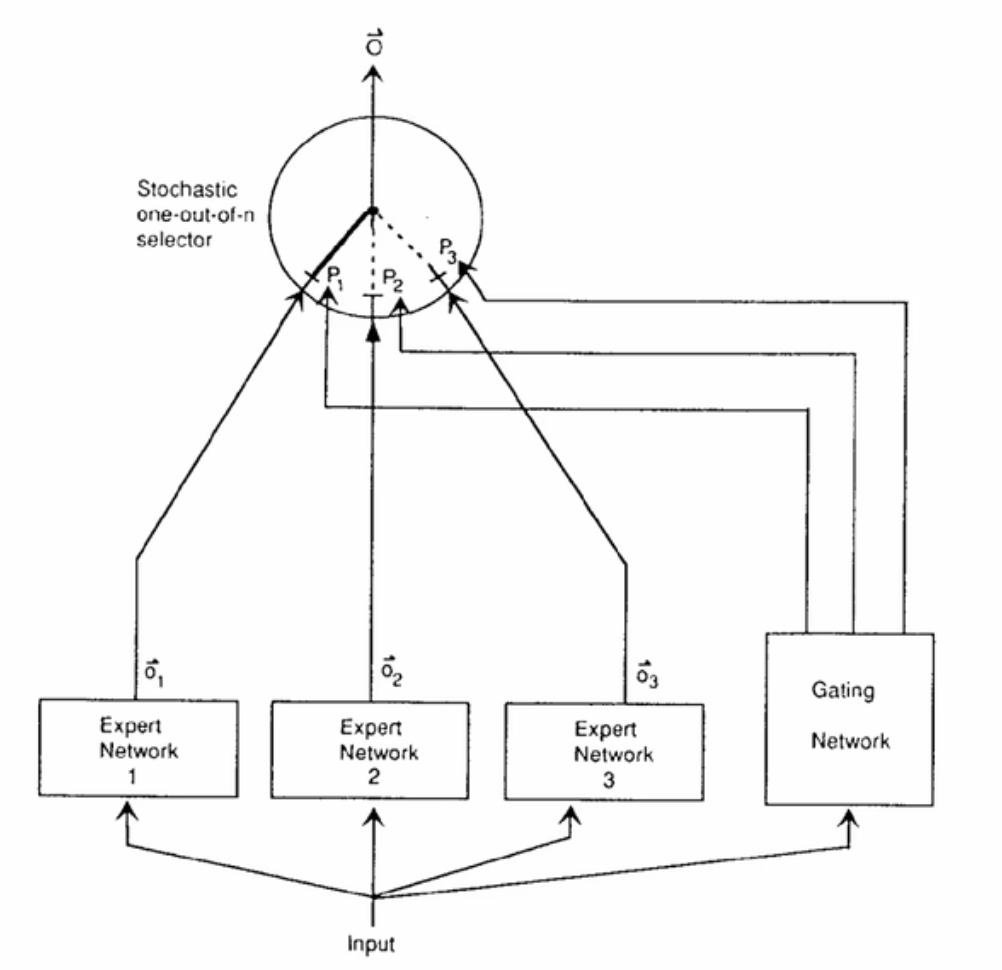
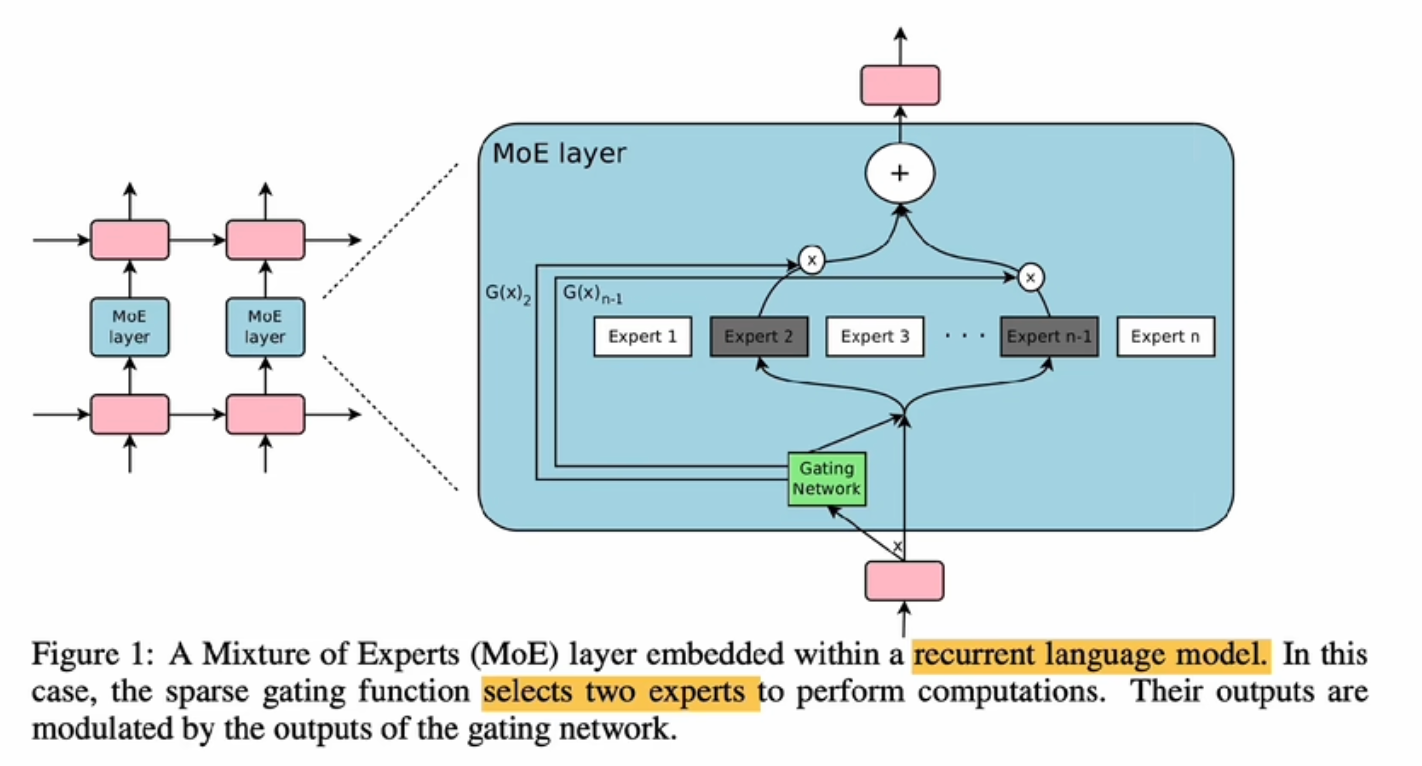
2017 把MoE层放进了RNN中,替换其中的一些网络层
“为什么说得宜于MoE,可以做到快速训练”
计算只经过部分专家,大大减少了计算量,解决了RNN训练慢,网络层数没办法太深
2020 Gshard 第一个MoE + Transformer模型
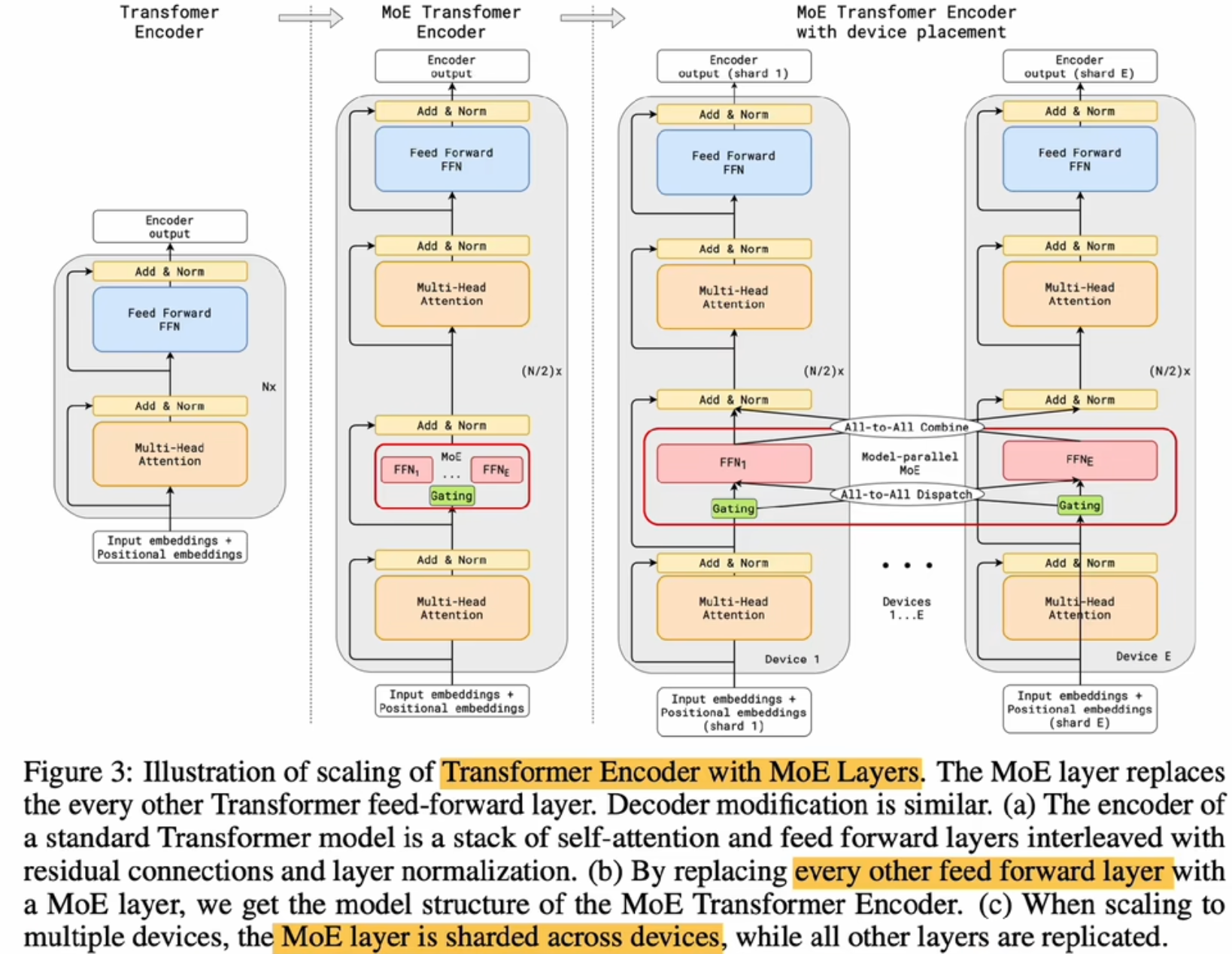
把transformer中的encoder和decoder的FFN层都换成MoE
优势:
搞拓展性:600B参数量
灵活性:每次只激活两个专家,虽然说整体的参数了巨大,但是在推理的时候之后部分参数会被激活
自动分片:多集群部署、运算 使用于大的集群部署,每一个专家单独部署到一个硬件上,就可以让我的整个网络做到一个快速响应。
劣势:
高通信开销:分片内容拷贝(TPU单卡能力不如GPU,但它的通信能力非常强 现在HW也在做这个事情)
实现复杂:MoE模型往往难以训练
负载平衡:专家激活不均匀
Top-K专家到Top-1专家 的switch transformer
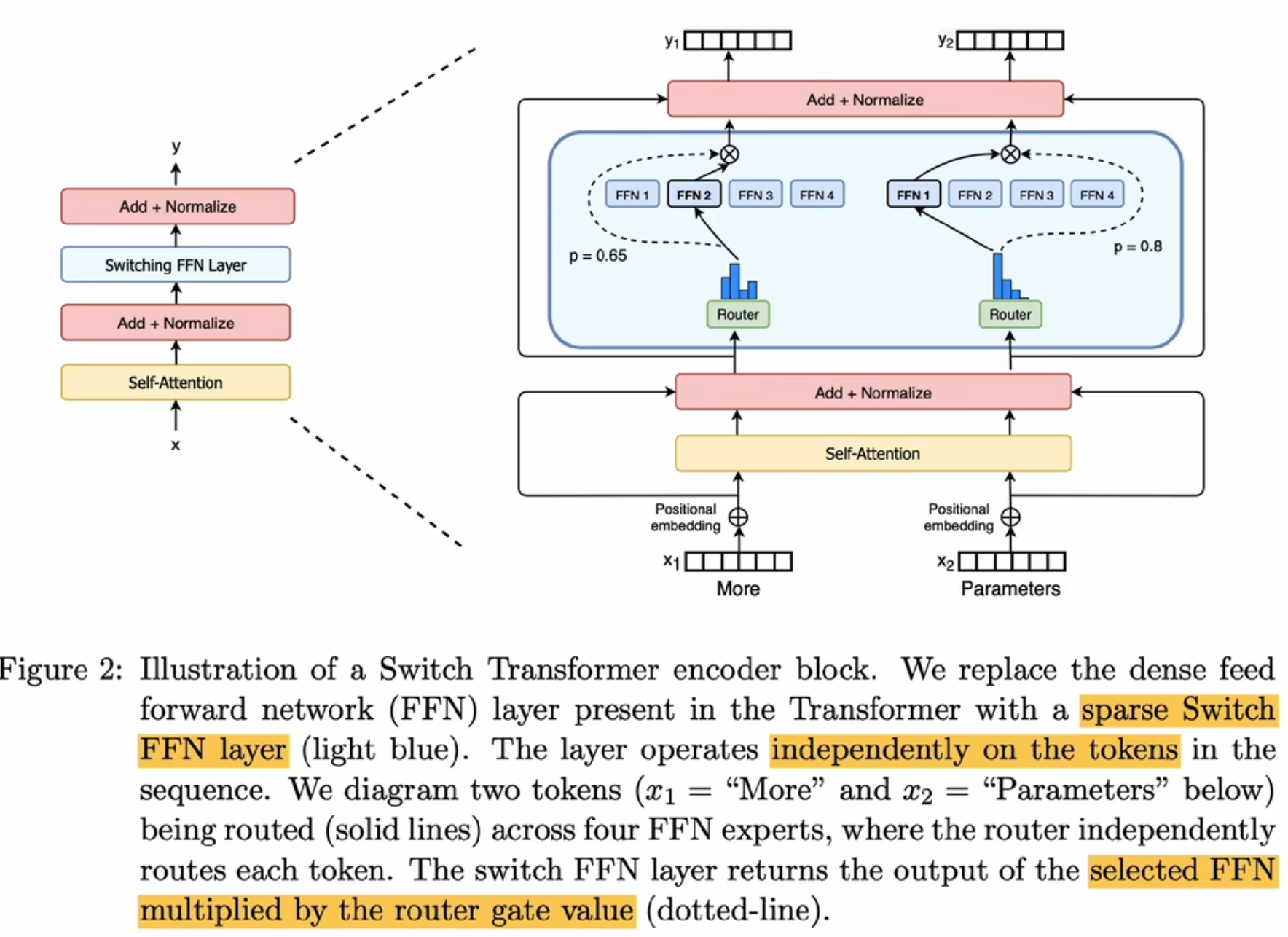
简化路由Rotter计算,只需要一个专家的意见就好;降低了通信成本;简化实现,利于训练和调优
参数量拓展到1.6T
“大模型这条路上,只有decoder only是走的通的?”
“Mistral模型7B 吊打Llama?高效推理|处理长序列|高内存效率”
- Mistral
- 滑动窗口注意力
- 使用GQA、SWA(Sliding Window Attentioin)滑动窗口注意力机制
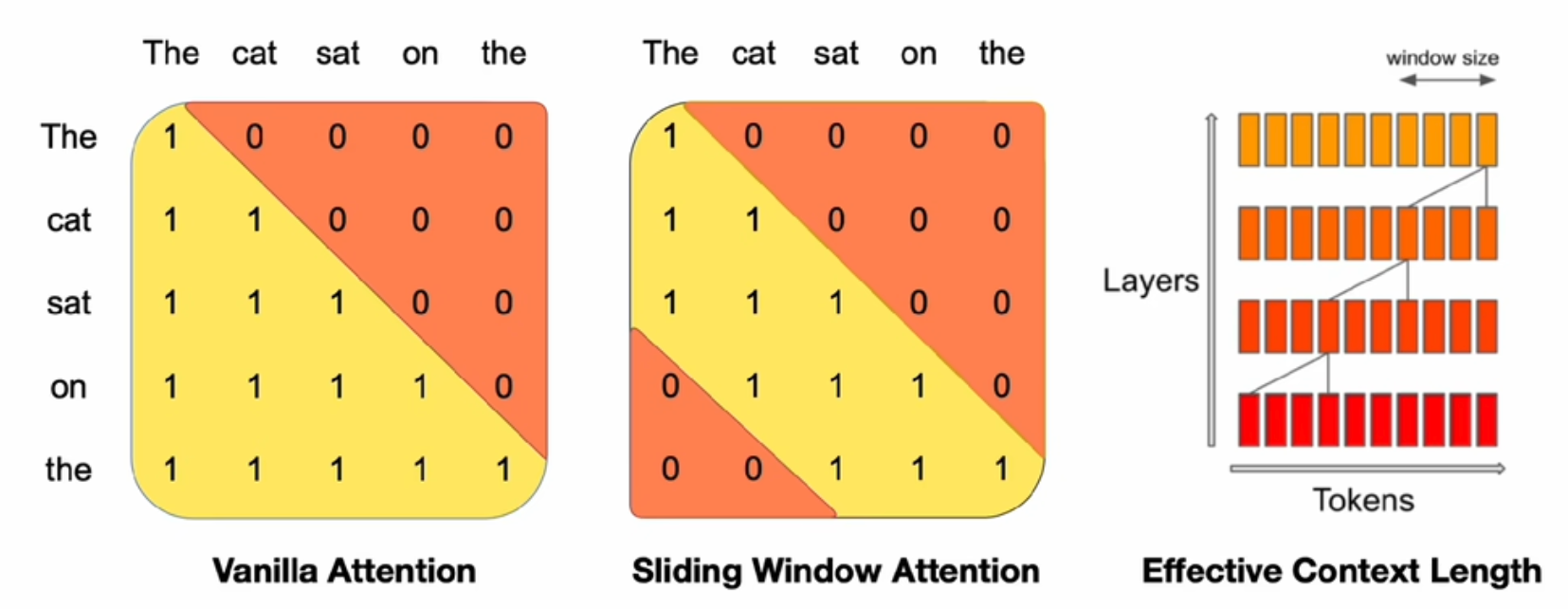
- SWA存在一个全局感受野机制,所以并不会因为窗口限制而忘记前面的信息
- 滚动缓冲区(rolling buffer cache),锁定缓存区大小,代替 i%W 部分
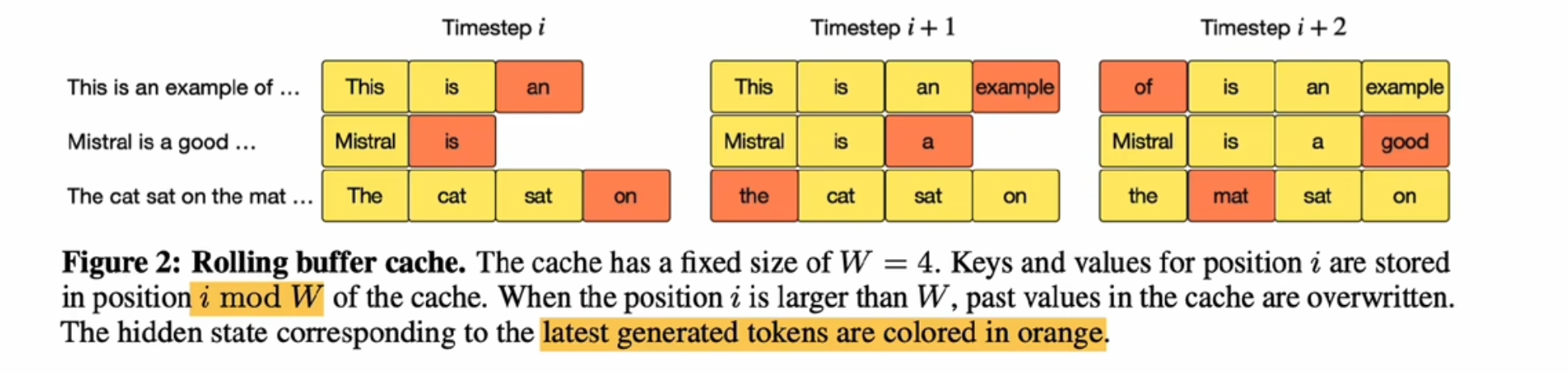
- 在处理一个序列的时候,如果这个序列的长度超过了缓冲区的大小的话,每一次都会把它放到一个imote w(i:这个词在序列里面位置编号) 然后用i整除w(w:缓冲区的大小)
- eg:w=4,i=5,那么i%w=1,那么就放到imote 1的位置
- 预填充和分块儿(pre-fill and chunking)把prompt预填充;数据分块儿
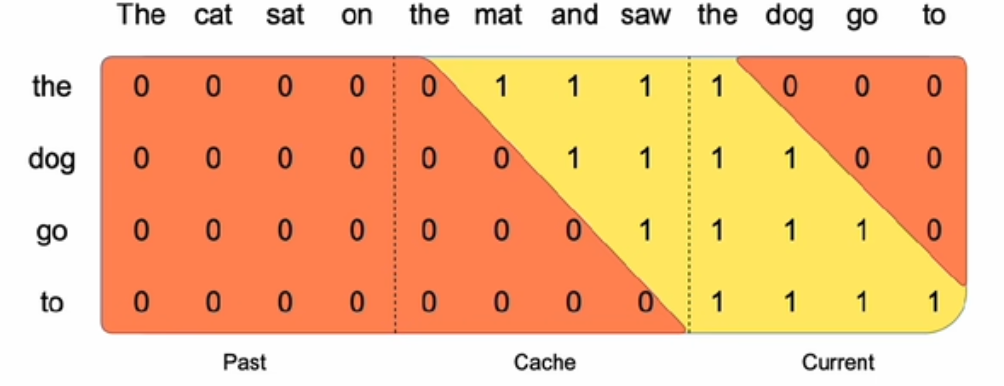
- 可能会造成长序列遗忘前面部分的问题
- 滑动窗口注意力
- Mixtral 8*7B
混合专家模型对标 Llama70B
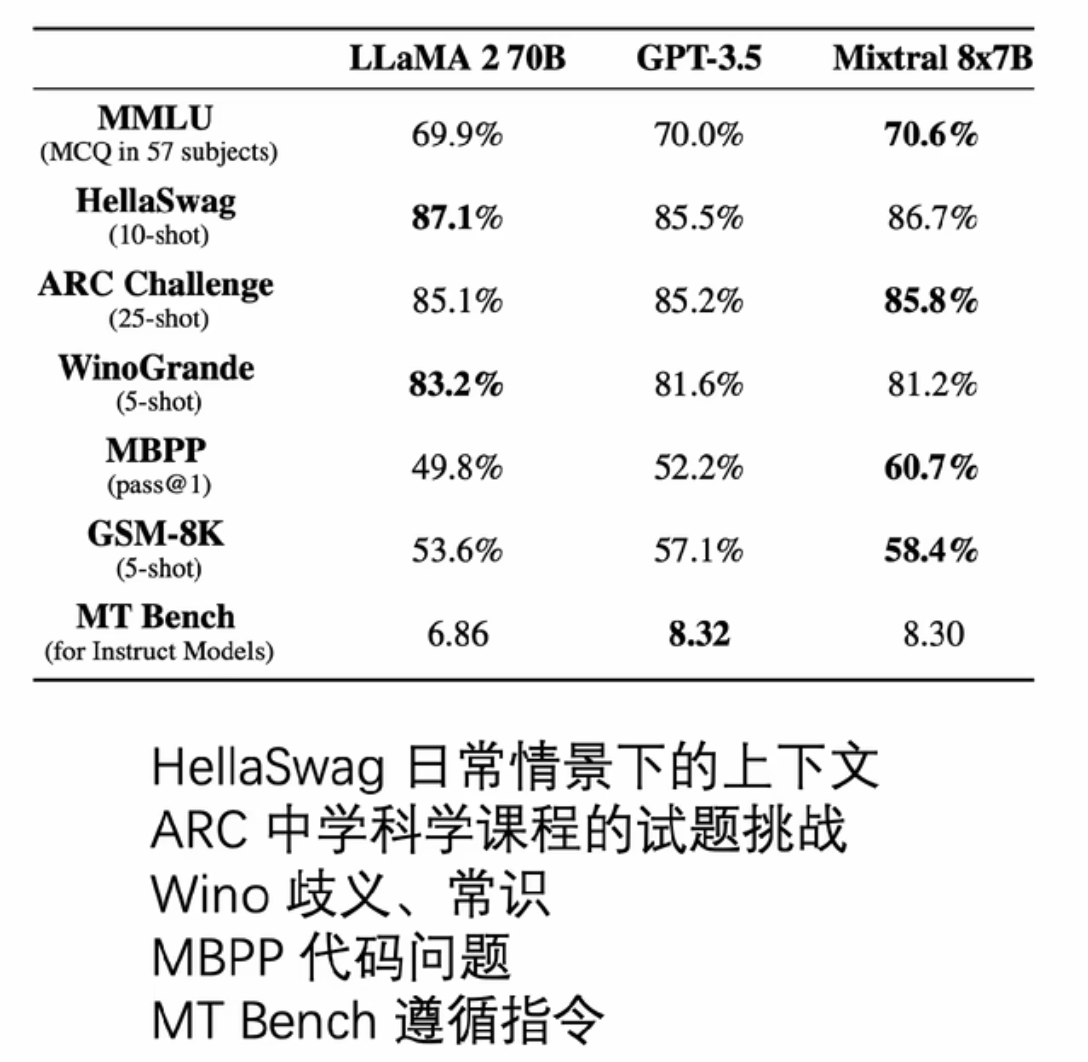
总体积在47B,但每次激活只激活13B(但是对于显卡来说还是需要保存47B的参数,但是因为每次只激活两个专家,所以在KVcache部分还是比dense的模型少很多,同参数量下的显存消耗也会少很多)
长文本能力 32k
DeepSeek 模型分类
从官网我们可以看到DeepSeek的模型大致包括
- DeepSeek LLM
- DeepSeek Math
- DeepSeek Coder
- DeepSeek V2
- DeepSeek VL
- DeepSeek Coder V2
- DeepSeek V3
- DeepSeek R1
其中的Math与Coder版本,大致指的是在数学和代码方面做过特殊的优化
- LLM:
- DeepSeek LM 模型使用与自回归 Transformer 解码器模型 LLaMA 相同的架构。7B 模型使用多头注意力 (MHA),而 67B 模型使用分组查询注意力 (GQA)。
- Sequence Length = 4096
- DeepSeek LLM 7B base
- DeepSeek LLM 7B chat
- DeepSeek LLM 67B base
- DeepSeek LLM 67B chat
V2
V3
R1
V2 V3 都属于MOE模型
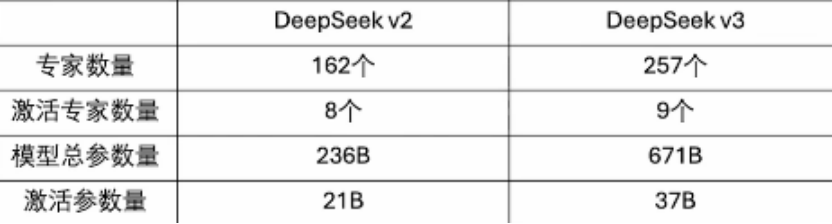
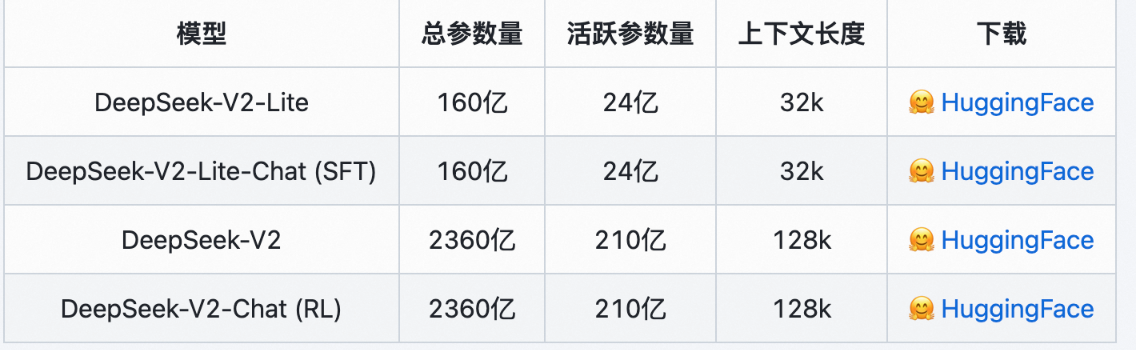
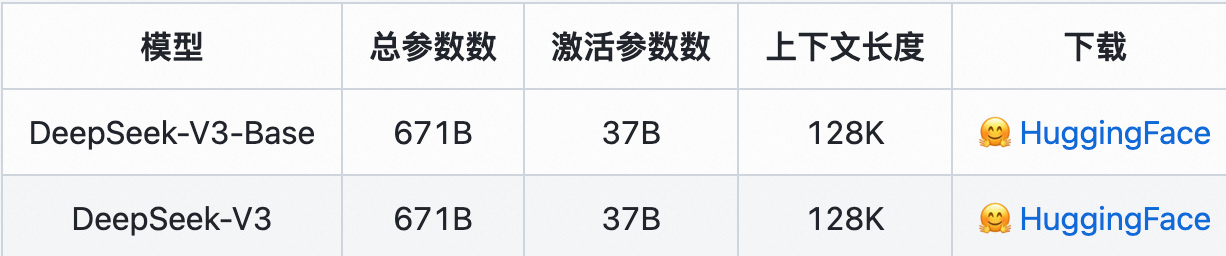
DeepSeek 模型
DeepSeekV2-价格屠夫
- 幻方
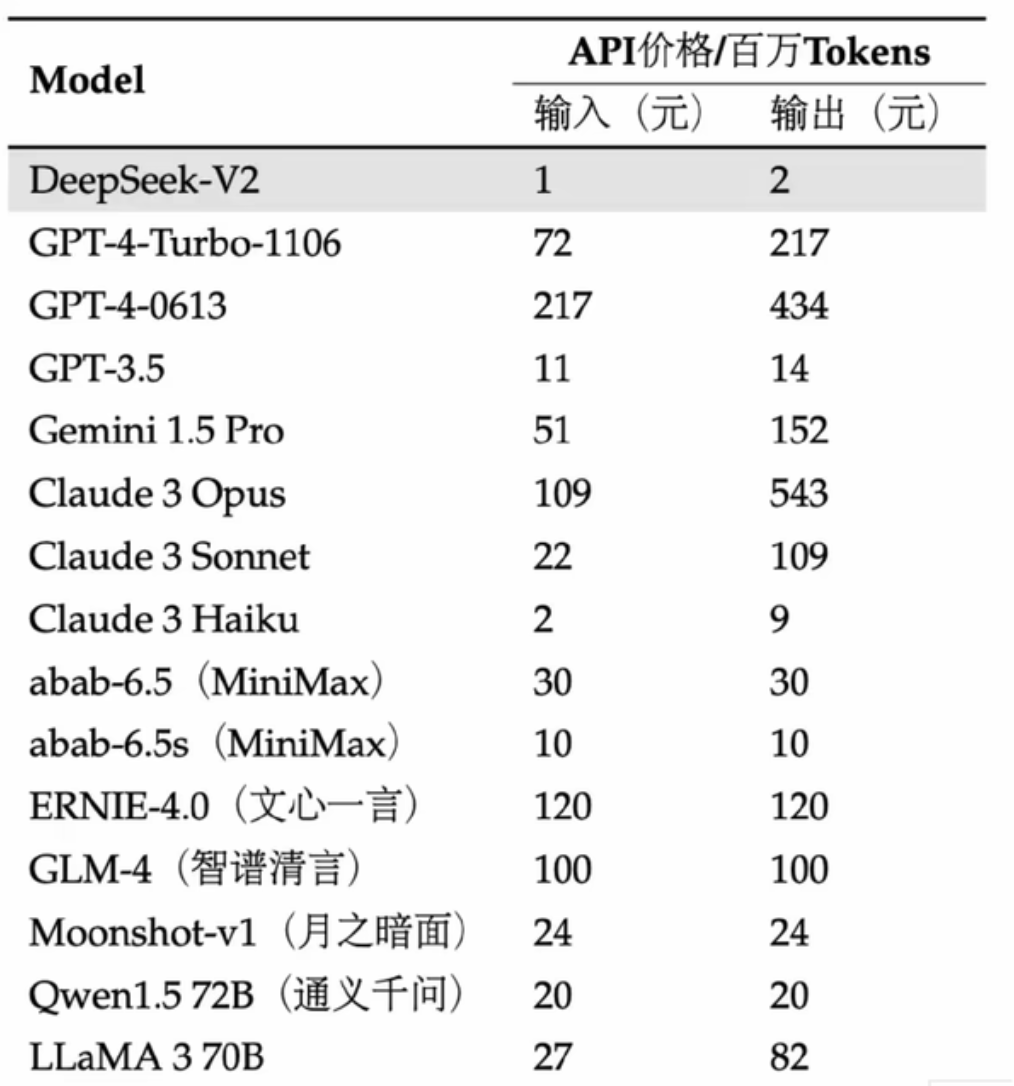
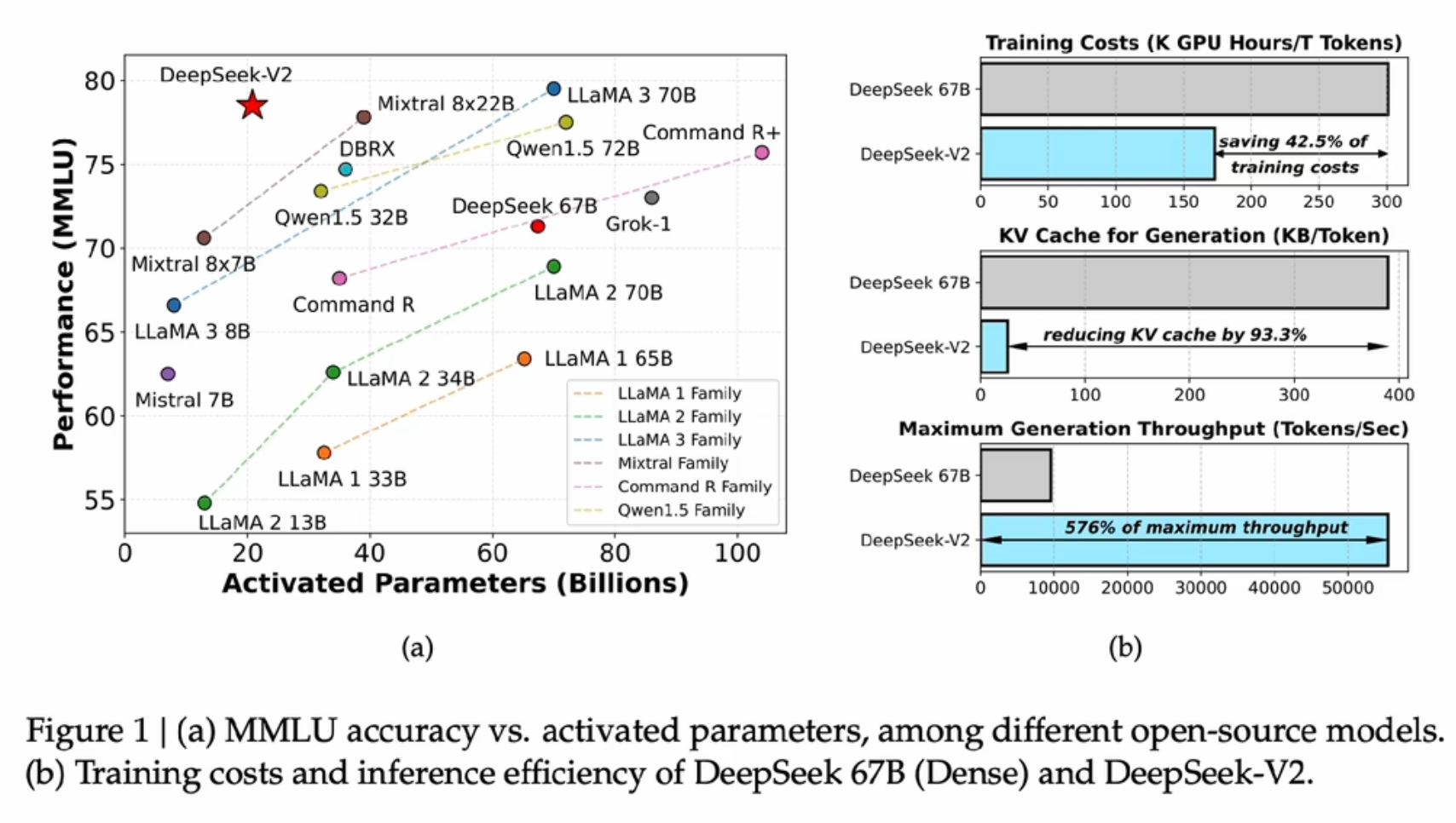
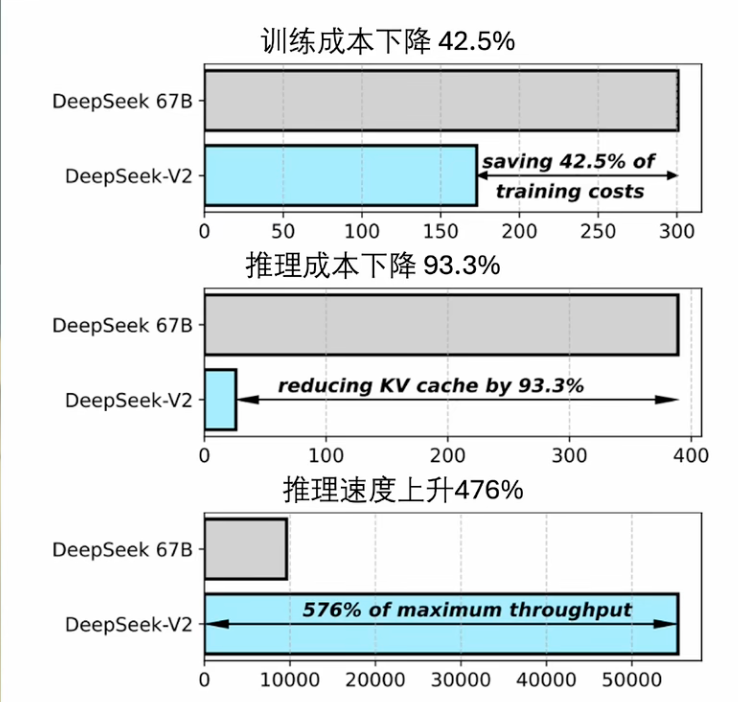
- training cost 和 显存开销 以及生成速度 都做了很强大的优化 所以在价格低廉的前提下还有的赚
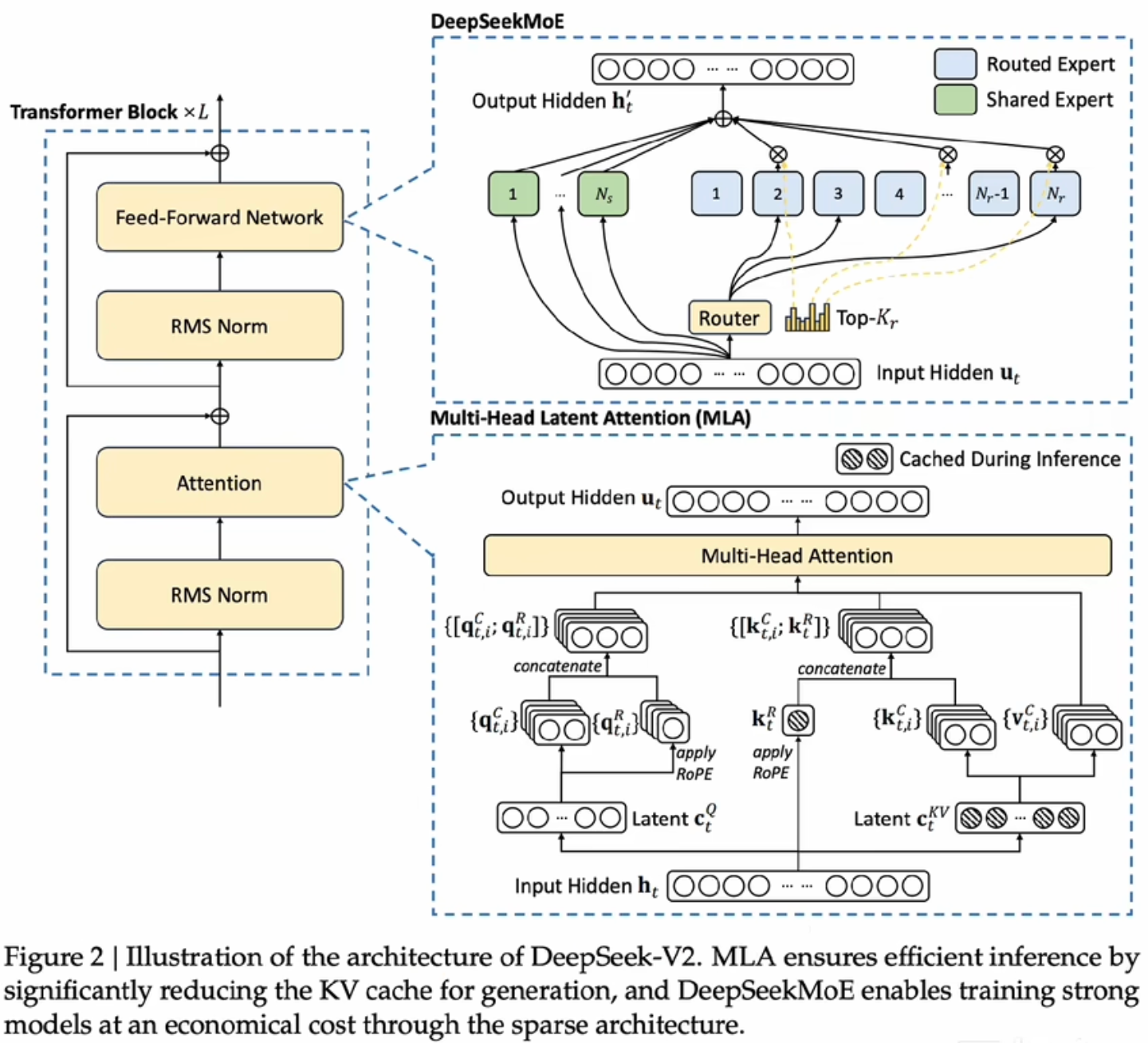
更好的混合专家策略以及注意力机制
-
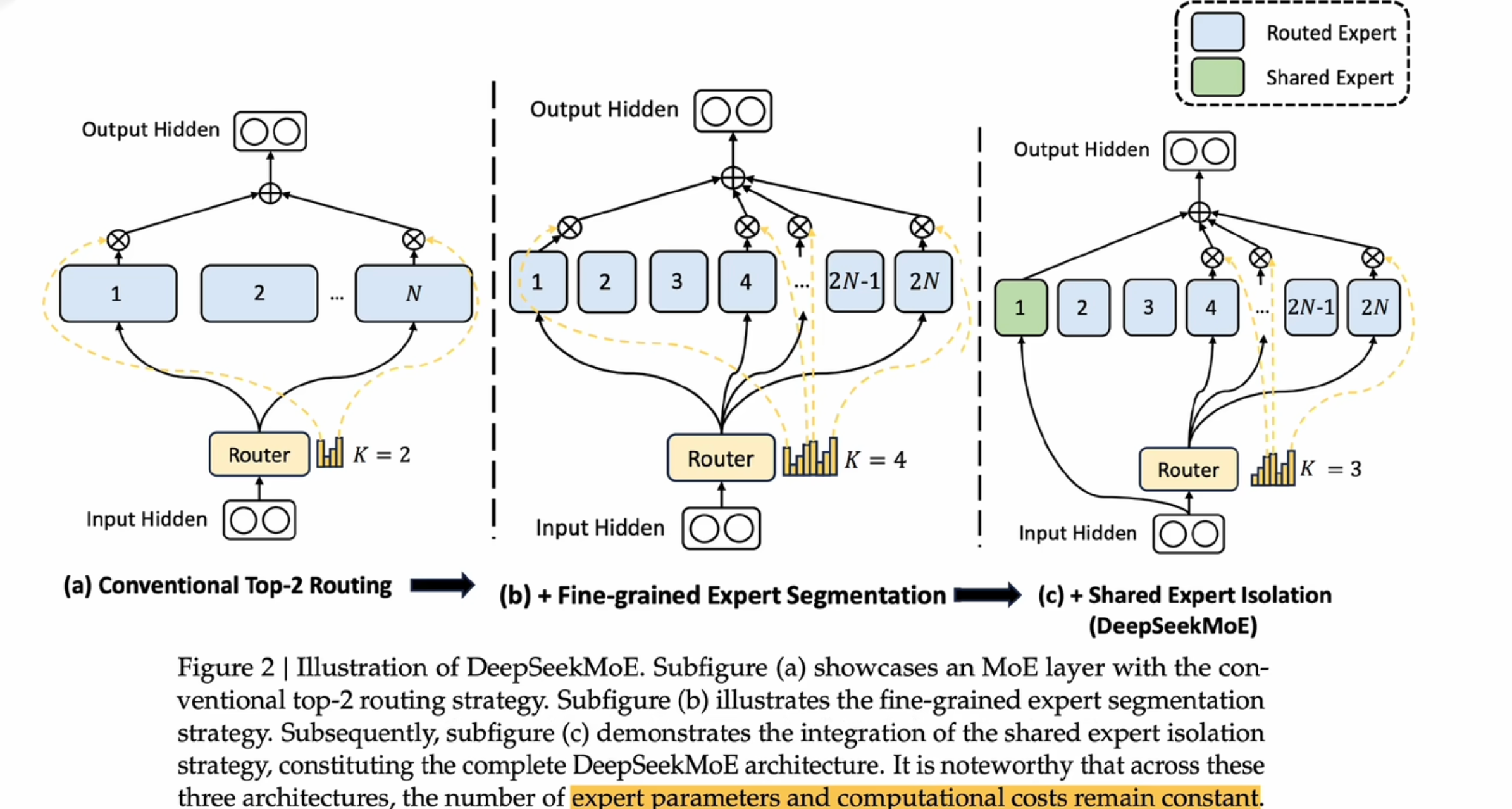
- 专家细粒度分割:将原来的N个专家分成2N个,同时每个专家的计算量也减少了一半
- 共享专家:绿色的专家处理一些每个专家共性的问题,减少了重复计算
- Mutil-Head Latent Attention
- 普通的Mutil-Head Attention,需要存储QKV三个权重矩阵,而Latent版本,则利用了分解矩阵的思想,利用几个低纬的小矩阵来代替一个高纬的大矩阵
DeepSeekR1
GPT o1:现有很牛的逻辑推理模型,它内在会做很多次的多轮思考,进行不断的反思。
scaling law:指数级的资源换回线性的增长
上海交大的团队在做一个o1的复制
https://github.com/GAIR-NLP/O1-Journey
- deepseek R1
- alpha-go | alpha-zero
- go系列是学习棋谱
- zero系列是从0开始,自己思考怎么去下围棋(强化学习的过程:制定规则,让模型自己去不断迭代,找到所谓的最优解)
- deepseek-R1-Zero:同样是一个pure- reinforcement-learning-model(纯强化学习模式)
- deepseek-R1:训练过程虽然也有SFT的步骤,但它对齐的不再是人类的“答案”,而是一个思考过程
- alpha-go | alpha-zero
“r1成功的一点也在于他是真正的“开源”也就是MIT协议;国内很多大模型厂商在7b、14b、32b是真开源,但在70b的时候就搞出了个什么“千问协议”;R1他是真正的把思考过程都展示给我们了,而我们看到的o1模型在这部分就做了很大的阉割,他不会把所有的cot思考过程都展示给用户”


