
Stable diffusion
Stable diffusion
服务器安装
1. 本地webui的安装
- 设备:macbook air m2
- 系统:ios15
- 安装homebrew
- 终端输入
/bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)" - 验证是否安装成功
brew -v得到输出Homebrew 4.4.0
最新版本才支持ios15
- 终端输入
- 安装python3、
brew install cmake protobuf rust python@3.10 git wget
- 更改阿里云下载镜像源
pip config set global.index -url https://mirrors.aliyun.com/pypi/simple
- clone文件
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 启动ui
cd table-diffusion-webui- 启动sd:
./webui.sh 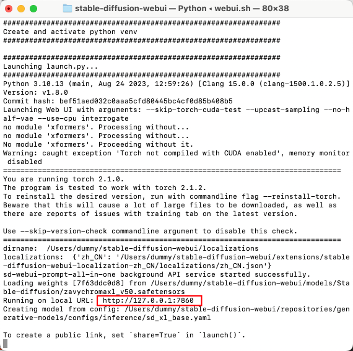
- 中文配置
- 双语语言包
- 在extensions(拓展)里面选择url安装,安装
- 然后apple setting
- 之后再到setting里面找到 bilingual localization 中选择zh_cn 然后apply 并 reload就可以啦
2. 使用说明
模型切换
C站:https://civitai.com/
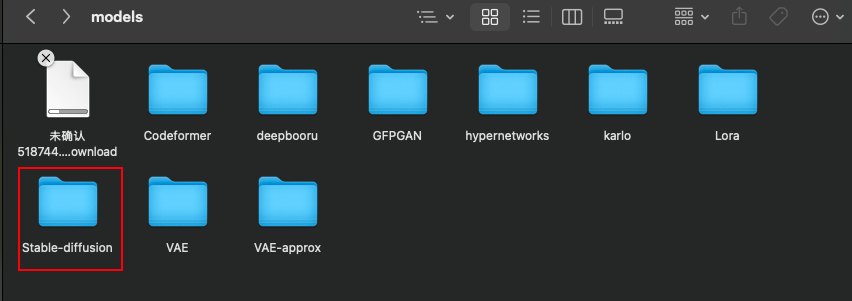
可以在c站下载所需要的模型,直接存到model对应的文件夹点击刷新就行,我们下载的模型是以safetensors结尾的,和大模型模型格式一样,注意一般的模型都是放在。
提示词
- 符号
1
2
3
4
5
6
7
8
9()小括号 权重值:red = 1 (red)=1.1 (((red)))= 1.331
【】 中括号 权重值:red = 1 【red】= 0.9 【【【red】】】=0.729
{}. 打括号 权重值:red = 1 {red} = 1.05 {{{red}}} = 1.15
<> 尖括号 主要用来调用lora < lora:文件触发权重>
_ 下划线 起连接作用 - 控制提示词生效时间
1
2
3
4
5
6
71.[提示词:0-1数值] 从指定点开始
2.[提示词::0-1数值] 从头到指定点
3.[提示词1:提示词2:0-1数值] 一人一半采样时间
4.[提示词1|提示词2] 交替采样 - 提示词
1
2
3
4
5
6
71 提示词之间用英文逗号分隔
2.提示词之间是可以换行的
3.权重默认为1,越靠前权重越高
4.数量控制在75个单词以内 - 推荐格式
1
2
3
4
5
6
7
8
91.画质词+画风词
2.画面主体描述
3.环境、场景、灯光、构图
4.Lora
5.负面词

采样器
分类:老派采样器|DPM采样器|新派采样器(UniPc,Restart)
3. 模型原理
- diffusion Model(扩散模型)
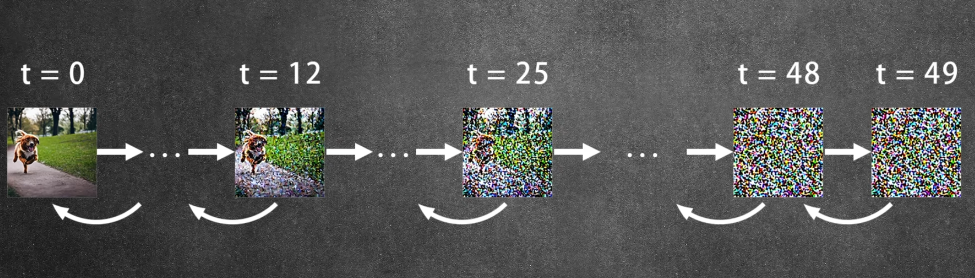
- Latent Diffusion Model(潜在扩散模型)Link
是扩散模型的一种变体,它是先把图片压缩,降低纬度,压缩后所在的空间就叫潜在空间,也就是latent space,这样可以大幅度减少计算量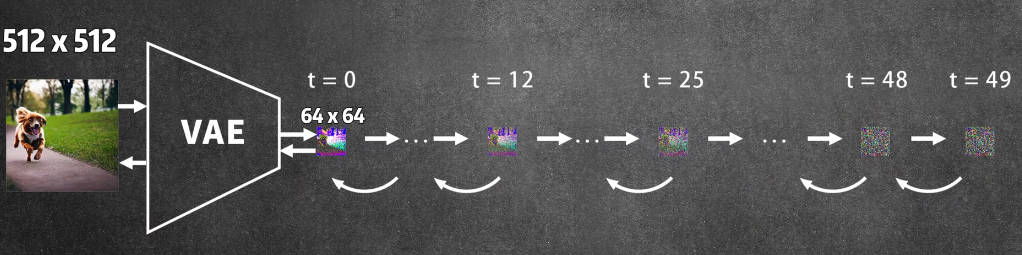
- Stable diffusion
基于LatentDiffusion开发出来的
- clip模型:这里用它的文本编码器,把文字转换成向量作为输入
- diffusion模型:用来生成图片,因为它是在图片压缩降纬后的潜在空间进行,所以扩散模型的输入和输出都是潜在空间的图像特征
- VAE模型:用它的解码器,把潜在空间的图像特征还原成图片
3.1 diffusion部分:
在一张图片上,我们随机的添加一些噪声,也就是高斯噪声,一步一步添加,直到只剩噪声,再训练一个网络把它从噪声恢复到原图
为什么要噪声?为什么要一步一步来?
因为直接移除像素回导致信息丢失,添加噪声则可以让模型更加学习到图片的特征,而且随机噪声还增加了模型生成时的多样性,而一步一步的来可以控制这一过程,同时提高了去噪过程中的稳定性
每一步添加多少噪声,根据schedule来决定,不同的schedule有不同的方法,可以是每次相同的量,也可以是一开始加的多后面加的少,先少后多比较好,图片特征损失的比较慢
因为高斯噪声可以直接相加,所以训练的时候直接把随机数量的噪声添加进图片,让训练的网络(u-net)还原图片
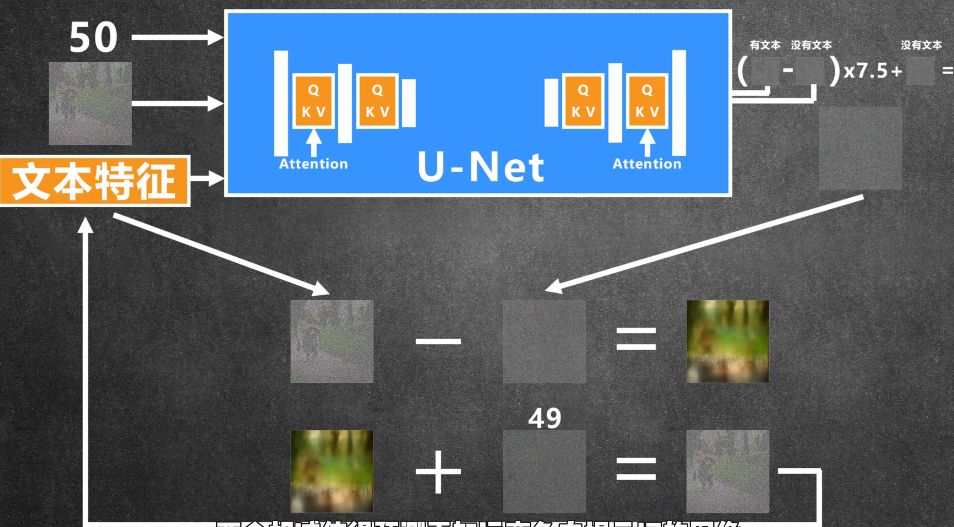
如何把文字内容加进去引导图片生成我们想要的内容
首先先用CLIP模型把文字(只支持英文)转化成文本特征,然后把文本特征加入到u-net中,u-net中添加了attention
优化方法:classifier free guidance
3.2 VAE Variational Autoencoder 变分自编码器
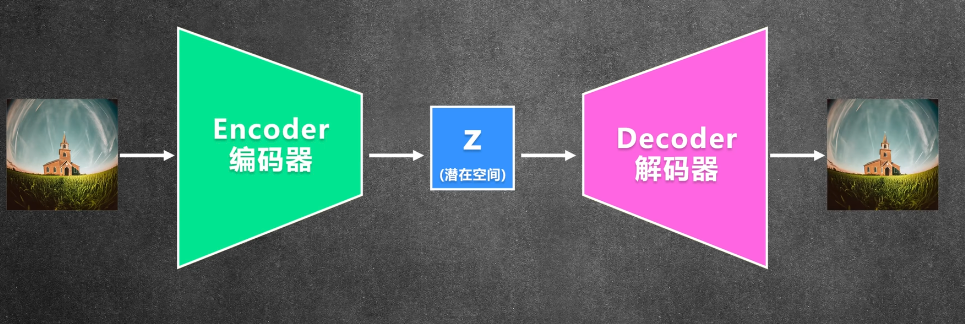
压缩图片:减少训练时间和硬件需求,但因为时压缩过再还原,会损失掉一些细节
由一个编码器和一个解码器组成,编码器把输入的图像压缩成潜在空间,解码器把潜在空间解码成图像,同时编码器和解码器之间还有一层变分层,这个层用来学习图像的分布,使得生成的图像更加平滑,同时编码器和解码器
3.3 CLIP contrastive Language-Image Pre-training
用文字和图像做对比的预训练模型,把文本和图像联系起来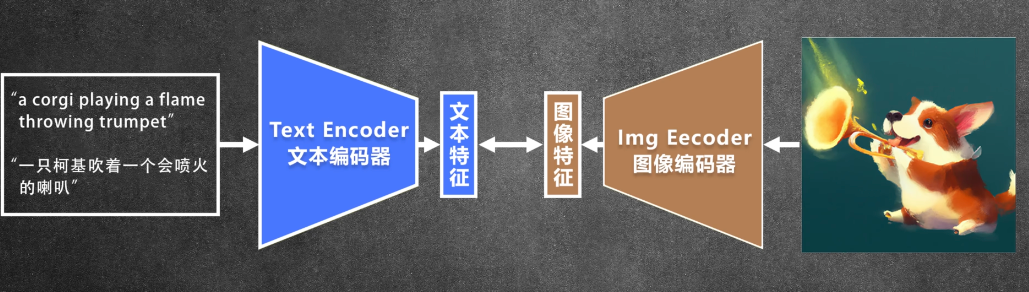
3. 模型训练link
训练自己的模型可以在现有模型的基础上,让AI懂得如何更精确生成/生成特定的风格、概念、角色、姿势、对象。
3.1 SD模型微调方法
主要有 4 种方式:Dreambooth, LoRA(Low-Rank Adaptation of Large Language Models), Textual Inversion, Hypernetworks。它们的区别大致如下:
- Dreambooth 是对整个神经网络所有层权重进行调整,会将输入的图像训练进 Stable Diffusion 模型,它的本质是先复制了源模型,在源模型的基础上做了微调(fine tunning)并独立形成了一个新模型,在它的基本上可以做任何事情。缺点是,训练它需要大量 VRAM, 目前经过调优后可以在 16GB 显存下完成训练。
- LoRA 也是使用少量图片,但是它是训练单独的特定网络层的权重,是向原有的模型中插入新的网络层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法, LoRA 生成的模型较小,训练速度快, 推理时需要 LoRA 模型+基础模型,LoRA 模型会替换基础模型的特定网络层,所以它的效果会依赖基础模型。
- Textual Inversion (也称为 Embedding),它实际上并没有修改原始的 Diffusion 模型, 而是通过深度学习找到了和你想要的形象一致的角色形象特征参数,通过这个小模型保存下来。这意味着,如果原模型里面这方面的训练缺失的,其实你很难通过嵌入让它“学会”,它并不能教会 Diffusion 模型渲染其没有见过的图像内容。
- Hypernetworks 的训练原理与 LoRA 差不多,目前其并没有官方的文档说明,与 LoRA 不同的是,Hypernetwork 是一个单独的神经网络模型,该模型用于输出可以插入到原始 Diffusion 模型的中间层。 因此通过训练,我们将得到一个新的神经网络模型,该模型能够向原始 Diffusion 模型中插入合适的中间层及对应的参数,从而使输出图像与输入指令之间产生关联关系。
总儿言之,就训练时间与实用度而言,目前训练LoRA性价比更高,也是当前主流的训练方法。


