
大模型学习之微调
为什么需要PEFT微调
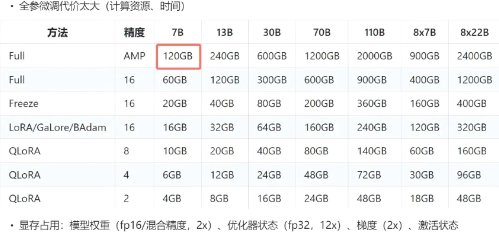
简单来讲就是全参微调代价太大
PEFT几种方式
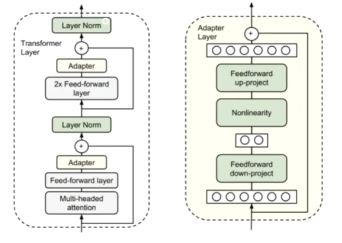
adapter
原理:
- 针对每个Transfomer层,增加两个Adapter结构(分别是注意力层和前馈层之后,但在norm之前)。训练时,固定原来预训练模型参数不变,只对新增的Adapter结构和Layer Norm层进行微调
缺点:
- 增加了模型层数,推理延迟
prefix tuning
原理:
- 在输入token之前构造一段virtual tokens作为prefix,训练时只更新prefix部分参数,其他参数不变
- 在每一层前端都加入virtual tokens
- 为防止直接更新prefix参数导致训练不稳定和性能下降,在prefix层前面加了MLP结构,训练完成后,只保留Prefix都参数
缺点:
- 额外token占用,降低有效序列长度
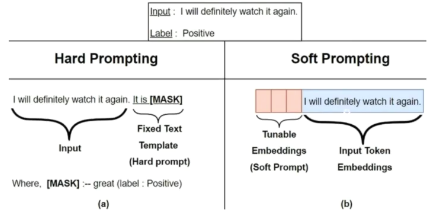
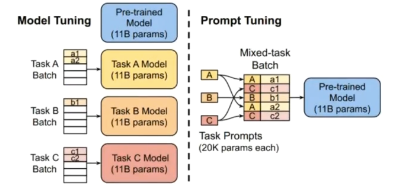
prompt tuning
原理:
- 给每个任务定义各自的prompt,拼接到数据上作为输入,但旨在输入层加入prompt tokens,且不加入MLP(显式加入token)
p-tuning
动机:
- prompt tuning中,prompt的构造方式对结果影响较大
原理:
- 将Prompt转换为可学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行表征(只在输入层)
- 与prefix tuning区别:只在输入层加,不一定在前面加,可在任意位置加
- 视为对prompt tuning对改进
缺点:
- v1 版本在小模型表现较差,NLU效果较好,序列标注效果较差
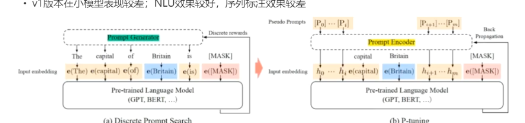
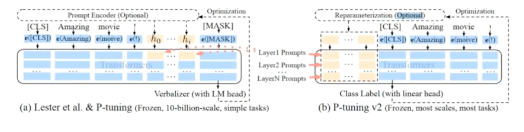
p-tuning v2
原理:
- 每层都加
- 移除重参数化编码器
- 更多可学习参数
- 不同任务提示长度不同
- 引入多任务
- 视为prefix tuning对改进
缺点:
- 微调后容易导致旧知识的遗忘
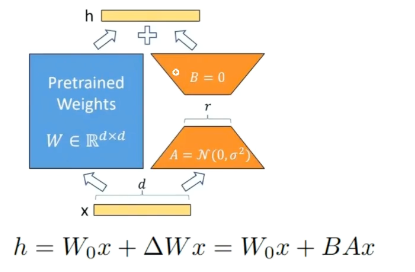
lora
原理:
- 通过低秩矩阵模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练
- 在原始的模型旁边增加一个通路,通过两个矩阵A,B相乘,先降纬再升纬。中间层纬度为r,模拟本征?
- 将两部分参数相加
- 其他:r一般取1,2,,4,8
lora变种
- lora+
- 给A、B设置不同的学习率
- lora-drop
- lora矩阵可添加到神经网络的任何一层,lora-drop可以选择那些层由lora微调,哪些层不需要
- adalora
- lora-drop中各层的适配器要么被完全训练,要么完全不被训练。而AdaLora可以决定不同的适配器具有不同的秩。
框架
- Llamafactory框架 国内开源
- SWIFT (魔塔)
微调主要参数设置
learing_rate:
根据gpt3 paper,一般来看,模型越大,学习率越小(无严格定义,实验导向)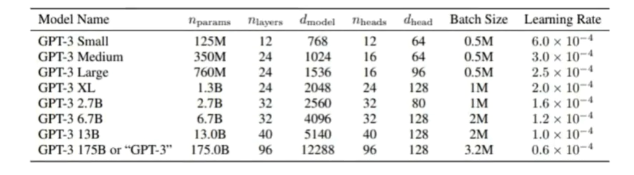
lr_scheduler_type 学习率控制器
- 常数学习率(constant):学习率在整个训练过程中保持不变
- 带预热的常数学习率(constant_with_warmup):在训练初期有一个预热阶段,学习率逐渐增加到初始学习率,然后保持常数
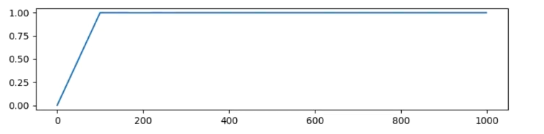
- 线性衰减(linear):从初始学习率下降到0
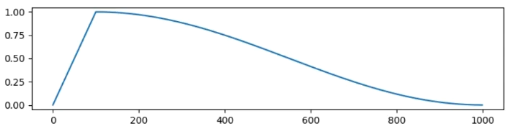
- 余弦退火(cosine):学习率按照余弦函数变化,在训练过程中逐步减小
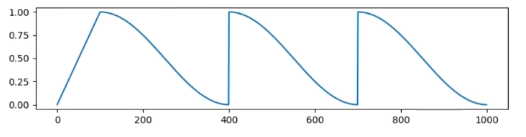
- 余弦退火与重启(cosine_with_restarts):带重启的余弦退火调度器,在训练过程中周期性地重置学习率,然后按余弦函数衰减,每隔一段时间重启余弦曲线
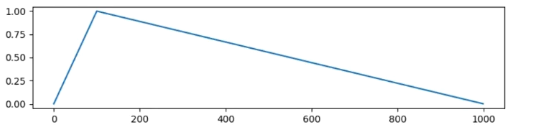
- 多项式衰减(polynomial):多项式衰减调度器,学习率按照多项式函数下降。
warmup_ratio 预热:
原理:
- 由于模型的权重是随机初始化的,刚开始训练时若学习率较大,可能带来训练不稳定。选择warmup预热学习率的方式,可以使得开始训练的几个epoch或者一些step内学习率较小
计算

- gradient_accumulation_steps:
- 梯度累加:每次获取一个batch的数据,计算1次梯度,梯度不清空,累加到预设值之后,再更新网络参数,然后清空梯度,进行下一次循环
- per_device_train_batch_size:每卡的batch_szie数量
- sft数据
- META(lima:less is more for alignment)
- 质量>>数量
- 多样性
- 高质量
- 一致性
- 若面临混合调节需求(需要在多种数据集tune,获取不同能力)
- 跷跷板现象
- 通用能力下降(灾难性遗忘)
- DMT(双阶段混合微调)
- 第一阶段在特定任务数据集进行多任务训练(如代码,数学推理等)
- 第二阶段使用混合数据进行SFT,包括通过数据和一定比例k的特定任务数据
Llamafactory_FT_Qwen案例
基于Llamaindex微调qwen2.5-7b
1.数据集准备
https://www.cnblogs.com/chentiao/p/17386131.html
2.服务器搭建
由于算力限制选择阿里云服务器
https://free.aliyun.com/?spm=a2c4g.11174283.0.0.46a0527f6LNsEe&productCode=learn
https://help.aliyun.com/document_detail/2329850.html?spm=a2c4g.2261126.0.0.f3be1d2ddJscIy
3.Qwen2.5-7b
!git lfs install 记得下载lfs不然无法下载完整的模型文件
!git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
4.Llamafactory
拉取环境
!git clone https://github.com/hiyouga/LLaMA-Factory.git
cd到Llamafactory目录下,加载依赖项!pip install -e .[torch,metrics]
4.1加载数据
将转换好的.json数据放入Llamafactory中的data文件中,并修改配置文件data_set.json
1 | "train": { |
4.2trian
cd到Llamafactory目录下!llamafactory-cli webui 启动webui界面
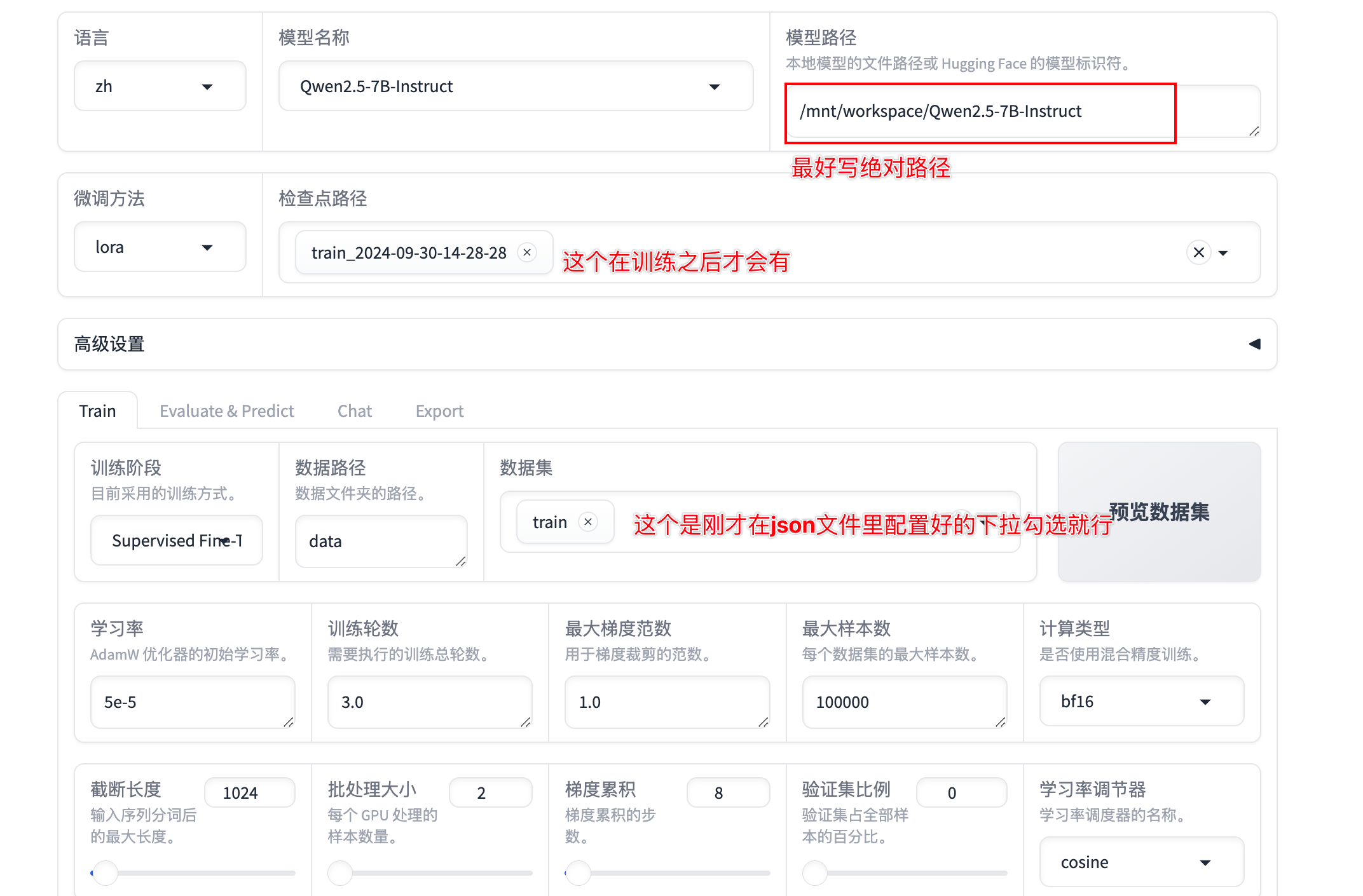
下拉找到训练就可以开始微调训练
参数配置
train中的可选参数很多,这里先搁置不进行一一介绍,感兴趣的小伙伴可以自己先进行了解
4.3Evaluate & Predict
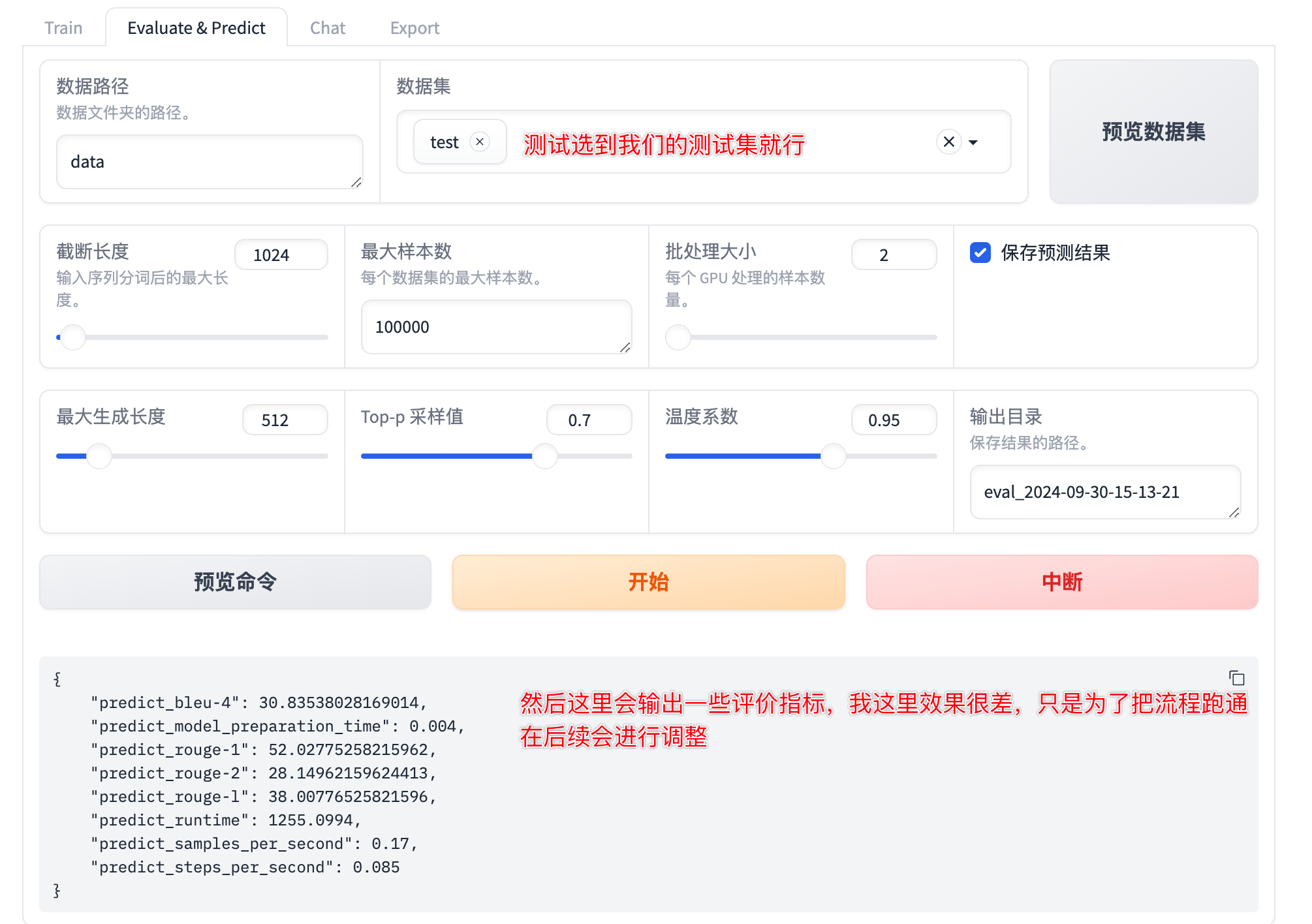
- 评价指标解释
predict_bleu-4 (30.835%):
BLEU-4分数(BiLingual Evaluation Understudy)BLEU是衡量机器翻译或文本生成模型输出与参考答案相似度的常用指标。bleu-4表示计算了4-gram的匹配率,数值越高表示预测的文本质量越高。predict_model_preparation_time (0.004秒):
模型在进行预测前的准备时间,通常指模型加载和初始化的时间,单位是秒。数值越小表示准备时间越短。predict_rouge-1 (52.03%):
ROUGE-1是文本生成评价指标之一,它衡量生成文本与参考文本之间的1-gram重叠程度。rouge-1的数值越高,代表模型预测的词汇与参考答案越接近。predict_rouge-2 (28.15%):
ROUGE-2同样是ROUGE系列指标之一,衡量2-gram的重叠率。和ROUGE-1一样,数值越高,代表模型输出的文本与目标文本越接近。predict_rouge-l (38.01%):
ROUGE-L使用最长公共子序列(LCS)来衡量模型生成文本和参考文本之间的相似度。该指标更关注文本的顺序结构,数值越高代表输出文本在顺序上与参考答案更相似。predict_runtime (1255.0994秒):
这是模型进行预测所花费的总时间,单位为秒。该值通常会随模型复杂度、硬件配置以及数据集大小而变化。predict_samples_per_second (0.17 样本/秒):
这是模型每秒能够处理的样本数。值越高表示模型的处理效率越高。predict_steps_per_second (0.085 步骤/秒):
这是模型每秒执行的步骤(steps),每个步骤通常包括一次前向传播和梯度更新。数值越高,表示模型在预测过程中的计算效率越高。
4.4Export
(chat部分就是一个聊天界面,可以在线测试微调后的效果)
Export是将我们微调的模型进行导出,我的理解是(将训练好的lora部分和原本的模型进行合并)
这部分只用设置输出路径就可以进行导出了
5部署
5.1 Ollama部署
在服务器上部署
首先拉取ollma文件
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.3.12
新建创建 Modelfile 文件,写入
FROM ./your_model_path
- 在ollama文件中创建模型
ollama create mymodel -f Modelfile
Llama.cpp
如果在ollama创建模型文件的时候遇见
Models based on 'Qwen2ForCausalLM' are not yet supported的问题,可使用llama.cpp,导出gguf格式的文件再进行部署推理首先拉取llama.cpp文件
!git clone https://github.com/ggerganov/llama.cpp.git1
2
3
4
5
6
7
8# 需要安装相关的库
cd llama.cpp
pip install -r requirements.txt
# 验证环境
python convert_hf_to_gguf.py -h
# 使用脚本进行模型转换,可以选择量化方式
python convert_hf_to_gguf.py ../yourmodelpath --outfile out_file_name.gguf --outtype f16
得到.gguf文件
然后重新使用ollama create mymodel -f Modelfile创建模型
得到.gguf文件
然后重新使用ollama create mymodel -f Modelfile创建模型,Modelfile是一个指向文件,需要指到gguf文件的路径,还可以在里面配置一个模型参数。
解决方式:
1 | #在modelfile文件中对大模型参数进行配置 |
- 最后使用ollama推理
ollama run mymodel
ollama常用指令:
1 | ollama serve # 启动ollama |


