
数据库
如何选择合适的数据库?
1结构化数据/非结构数据
1.1 结构化数据(structured data)
有固定格式或模式的数据,通常可以用表格的形式来表示,每一列对应一个字段,每一行代表一条记录。
特点:固定格式|易于处理|标准化
- 应用场景:
- 关系数据库:MySQL,PostgreSQL
- Excel,CSV,json/xml
1.2 非结构化数据(unstructured data)
非结构化数据是没有固定格式的数据,通常包含大量的文本、图像、音频、视频等内容
特点:自由格式|难以处理|多样化
- 应用场景:
- 文本分析:如感情分析
- 图像识别:人脸识别,物体检测
- 语音识别:语音转文字,语音合成等
- 社交媒体监控:分析社媒帖子、评论
关系型数据库:(基于SQL)
关系型数据库由一组连接起来的表(比如CSV表)组成。表中的每一行代表一条记录。
所有的关系型数据库都使用类似SQL的语言进行查询,这些语言很常用,并且自带join操作(即连接操作,用于把来自两个或多个表的行结合),这种数据库支持对列进行索引,使得基于这些列能进行更快的查询。
常见的关系型数据库:MySQL,PostgreSQL,SQLite,Oracle,SQL Server,DB2等。
NOSQL数据库
- 文档存档数据库: 文档存储数据库的原子单位是一个文档(document),每个文档都是一个json,不同文档可以有可以有不同schema,包含不同的字段。文档存储数据库允许对文档中的某些字段建立索引,从而能够基于这些字段进行更快的查询
Milvus
Milvus是一个开源向量数据库,可以通过高维向量嵌入存储、索引和搜索数十亿级非结构化数据。它非常适合构建现代人工智能应用程序,例如检索增强生成 ( RAG )、语义搜索、多模态搜索和推荐系统。Milvus 可在从笔记本电脑到大型分布式系统的各种环境中高效运行。它可作为开源软件和云服务使用。
RAG 利用以向量形式存储的大型非结构化数据数据库(一种有助于捕捉数据之间的上下文和关系的数学表示形式),帮助常规大型语言模型 (LLM)理解上下文并减少幻觉。
向量数据库通过使用距离度量(距离越近意味着结果越相似)的相似性搜索来进行向量检索,例如欧几里得相似度、点积相似度或余弦相似度。
为了加速检索过程,使用索引机制来组织向量数据。这些组织方法的示例包括 平面结构、倒排文件 (IVF) 、 分层可导航小世界 (HNSW) 和 局部敏感哈希 (LSH) 等。这些方法中的每一种都有助于在需要时提高检索相似向量的效率和有效性。
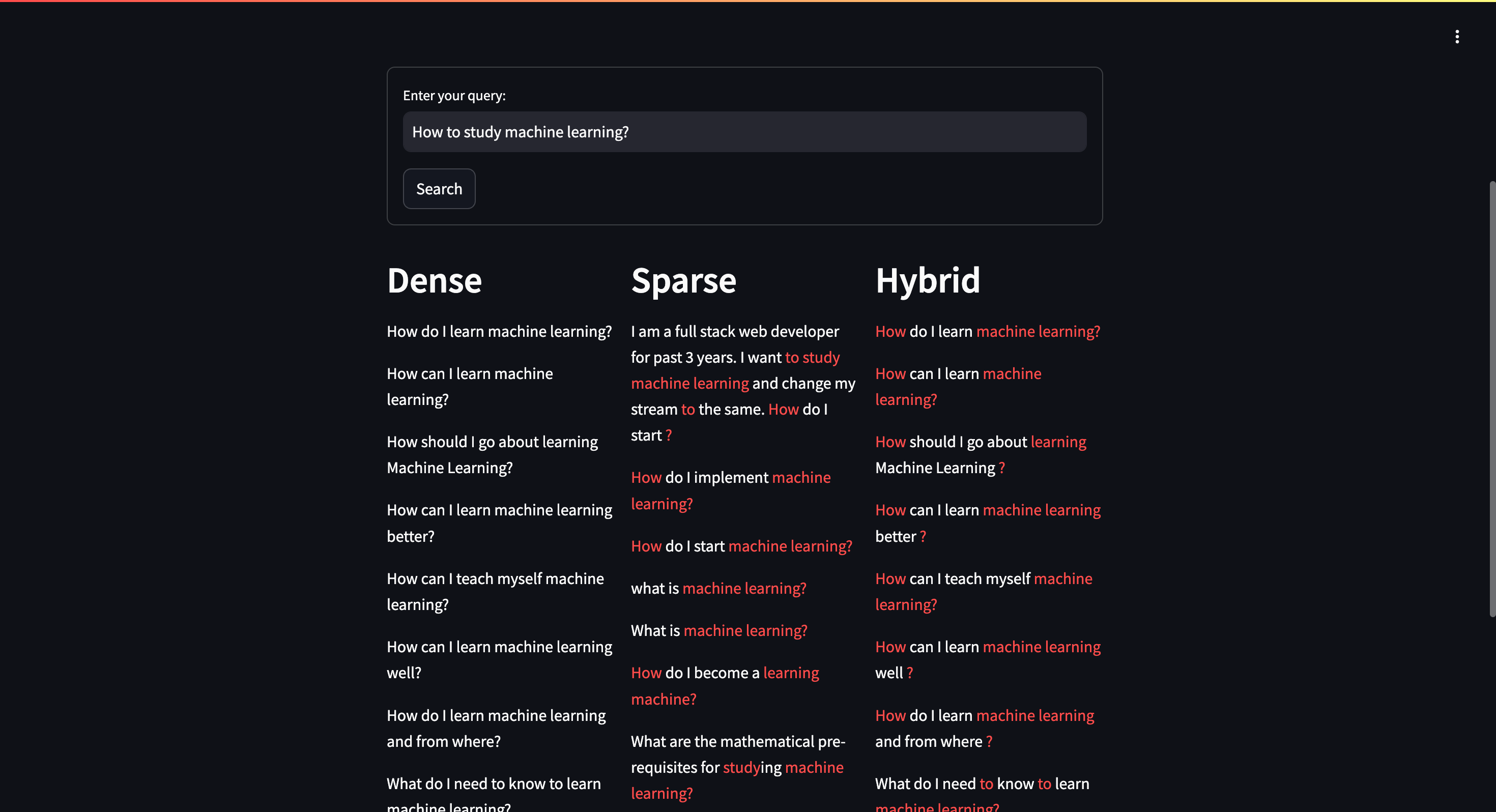
Milvus 支持密集、稀疏和混合检索方法:
- 密集检索:利用语义上下文来理解查询背后的含义。
- 稀疏检索:强调关键字匹配,根据特定的术语查找结果,相当于全文搜索。
- 混合检索:结合密集和稀疏方法,捕获完整的上下文和特定关键字以获得全面的搜索结果。
绩效指标
让我们看一下可以帮助您衡量矢量数据库性能的关键指标。
加载延迟衡量将数据加载到矢量数据库的内存中并建立索引所需的时间。索引是一种数据结构,用于根据相似性或距离有效地组织和检索矢量数据。内存索引的类型包括平面索引、IVF_FLAT、IVF_PQ、HNSW、可扩展最近邻 (ScaNN)和DiskANN。
召回率是指搜索算法检索到的Top K个结果中真正匹配或相关项目的比例。召回率值越高,表示相关项目的检索效果越好。
每秒查询数(QPS)是矢量数据库处理传入查询的速率。QPS值越高,表示查询处理能力越好,系统吞吐量也越高。
通过软件预取加速 Redis 向量搜索
Redis 是一种流行的传统内存键值数据存储,最近开始支持向量搜索。为了超越典型的键值存储,它提供了扩展模块;RediSearch模块可直接在 Redis 中存储和搜索向量。
对于向量相似性搜索,Redis 支持两种算法,即 brute force 和 HNSW。HNSW 算法专门用于在高维空间中高效定位近似最近邻。它使用名为candidates_set的优先级队列来管理所有用于距离计算的向量候选。
每个向量候选除了向量数据外,还包含大量元数据。因此,从内存加载候选时,可能会导致数据缓存未命中,从而导致处理延迟。我们的优化引入了软件预取功能,以便在处理当前候选时主动加载下一个候选。此增强功能使单实例 Redis 设置中的向量相似性搜索吞吐量提高了 2% 到 3%。该补丁正在上游进行中。
使用 BGE-M3 模型进行嵌入
BGE-M3 模型可以将文本嵌入为密集和稀疏向量。



