
部署
部署
边缘端部署
板子启动
烧录系统镜像
使用读卡器插入SD卡,然后使用Etcher软件进行烧录。(参考文档有详细步骤)
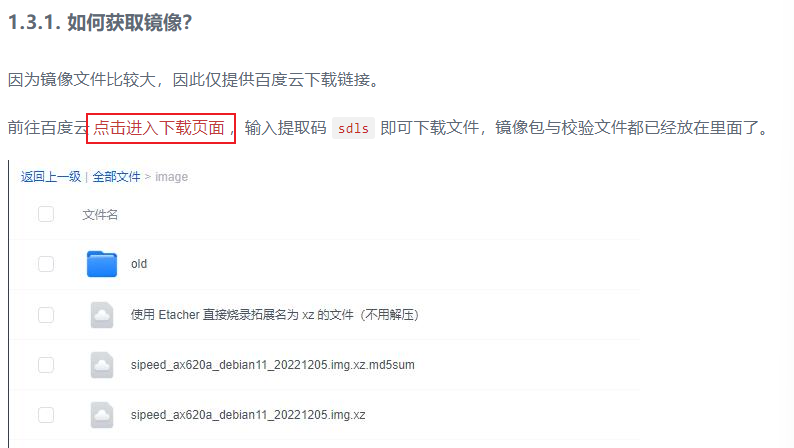
连接板子
这里使用MobaXterm进行连接,可以通过串口直接连接,以及网口,wifi等方式
常用的基础命令包括:
jupyter notebook 启动网页端notebook
ifconfig -a 查看当前网络配置
nmtui-connect 图形化联网
模型部署
要部署模型到
AXera-Pi,需要将模型量化到 ·INT8·,减小模型大小的同时提高运行速度,一般采用PTQ(训练后量化)的方式量化模型步骤:
1. 准备好浮点模型。
2. 用模型量化和格式转换工具转换成 AXera-Pi 支持的格式,这里工具使用爱芯官方提供的 pulsar3. 在 AXera-Pi 上运行模型。
安装docker
第一次尝试是安装windows版本的docker
然后拉取转换工具’docker pull sipeed/pulsar:0.6.1.2’
模型转换
pytorch 要求2.0,且yolov8,还得改explore的文件详细参考:模型导出
我们需要准备好我们训练好的基础模型,并通过yolo命令将它转换成onnx模式(有特殊要求的哦),这里特别的一点是opset=11
python yolo task=detect mode=export model=./runs/detect/train/weights/best.pt format=onnx opset=11选择镜像 创建容器:
docker run -it –net host –rm –gpus all –shm-size 8g -v D:/Docker:/data sipeed/pulsar
然后利用镜像中的工具对模型进行转换
pulsar build –input onnx/best.onnx –output rebar.joint –config config/rebar.prototxt –output_config rebar.prototxt
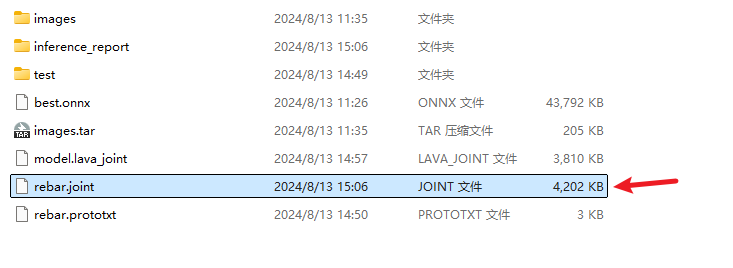
得到joint文件就可以开始进行边缘端部署了
模型部署
准备好joint文件以及验证文件,
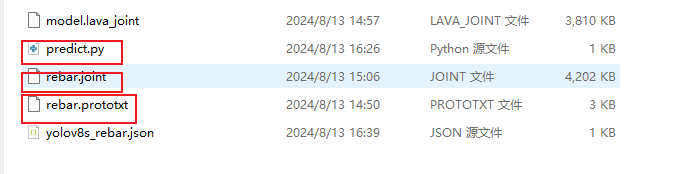
然后直接python3 predict.py就可以运行
开机自动启动文件在:boot里面的rc.local文件里的修改
安卓部署
ncnn打包 打包最新的yolov5 yolov8 可能会出现报错 选择AI模型的版本尽量选择稳定版 尽量不要去踩新版本部署的坑。
Android本身是存在版本兼容问题的,开发Android的时候需要虚拟机或者工程机,但是AI模型需要算力芯片所以用不了虚拟机
模型打包,模型接口,提供部署方案。
服务端、PC端部署(NVIDIA)
TensorRT部署
- 主要针对英伟达设备(可以应用在PC端,服务器,边缘端)
- TensorRT与CUDA一样是一个驱动,可以让电脑中的GPU平台来进行深度学习,CUDA主要做模型训练,TensorRT主要做模型的推理。 训练的时候核心是反向传播(链式求导),推理的核心是前向运算(矩阵运算)。
- TensorRT是个矩阵的并行运算框架,做反向传播能力很差,推理时速度要比CUDA快数倍甚至数十倍。 装TensorRT的前提需要装好CUDA onnx、libtorch、ncnn都是基于第三方框架,但是tensorrt无法跨平台
pytorch的模型转为onnx之后需要对onnx进行验证:
1 | # 验证onnx模型的结构是否正确 |
1.基础知识
TensorRT用于在英伟达GPU上做深度学习推理任务,通过利用GPU的并行计算能力,加速升级网络推断的速度,从而提升模型的实时性能,TensorRT可以通过层融合、混合精度、量化等技术显著提高深度神经网络的推理性能。同时支持python/c++,推理性能一致。
CUDA做模型的训练,训练的核心是反向传播(链式求导)|TensorRT做模型推理。训练的核心是前向运算(运算)
部署场景可以是PC端、服务端、边缘段,只要设备使用的是英伟达设备
在训练了神经网络之后,TensorRT可以对网络进行压缩、优化以及运行时部署,并且没有框架开销。
nvidia-smi 输出信息的解读
基本信息

NVIDIA-SMI Version:
nvidia-smi工具的版本。Driver Version:当前安装的 NVIDIA 驱动程序版本。
CUDA Version:支持的 CUDA 版本。这表明驱动支持的最高 CUDA 版本,可能与实际使用的 CUDA 库版本不同。
GPU状态部分

GPU:GPU 的编号。系统中的第一个 GPU 通常是 GPU 0,之后依次类推。
Name:GPU 的型号名称,如 Tesla T4 或 GeForce RTX 2080。
Persistence-M:持久模式状态。若为 “On”,则 GPU 不会在空闲时被禁用,这对高性能计算任务可能有帮助。
- 由于 Windows 的 NVIDIA 驱动与 Linux 驱动的行为有一些差异,Persistence-M 字段显示的是
Driver Model而不是传统的On或Off。具体来说,Windows 驱动模型下的Driver Model指的是 Windows 系统中 GPU 驱动的模式。 - 它通常显示两种模式:
- WDDM (Windows Display Driver Model):
- 这是 Windows 系统中的标准驱动模型,主要用于图形渲染任务(如桌面显示、游戏等)。
- 当
nvidia-smi显示Driver Model: WDDM时,表示该 GPU 主要用于图形任务,尤其是和显示器连接的图形卡。
- TCC (Tesla Compute Cluster):
- 这是 NVIDIA 提供的另一种驱动模式,专为高性能计算任务设计,不涉及图形渲染。
- 当
nvidia-smi显示Driver Model: TCC时,表示该 GPU 正处于计算模式,主要用于并行计算任务(如 CUDA、深度学习训练等)。这种模式通常在数据中心或 HPC(高性能计算)环境中使用。 - TCC 模式常见于专业级显卡(如 Tesla、Quadro 系列)中,而 GeForce 系列通常只支持 WDDM 模式。
- WDDM (Windows Display Driver Model):
- 由于 Windows 的 NVIDIA 驱动与 Linux 驱动的行为有一些差异,Persistence-M 字段显示的是
Bus-Id:GPU 在系统中的总线 ID,用于唯一标识每个 GPU。
Disp.A:是否启用了显示(Display Active)。若显示为
Off,则表示该 GPU 不连接到显示输出。Volatile Uncorr. ECC:显示是否有内存纠错的非易失性错误。如果为
0,表示没有发生错误。Fan:风扇转速的百分比。对于一些数据中心 GPU,如 Tesla 系列,风扇速度可能为
N/A,因为它们依赖于机架风扇。Temp:GPU 的温度(摄氏度)。典型的工作温度在 30C 至 80C 之间。
Perf:性能状态,表示当前的 GPU 运行模式。可能的值:
- P0:最高性能。
- P8:低性能状态(空闲时)。
- P12:更低的性能状态(深度空闲)。
Pwr:当前功耗及其最大额定功率。例如
13W / 70W表示当前功耗为 13 瓦,最大功耗为 70 瓦。Memory-Usage:GPU 显存使用情况:
- Used:已用显存,单位为 MiB。
- Total:总显存。
GPU-Util:GPU 使用率,以百分比表示。比如
0%表示 GPU 处于空闲状态,100%表示完全利用。Compute M:当前的计算模式:
- Default:表示默认模式,允许图形和计算工作负载。
- Exclusive_Process:每个 GPU 只能被一个进程使用。
Active Processes (GPU 工作进程)

PID:进程 ID,标识使用 GPU 的进程。
Type:进程类型:
C:计算进程(CUDA)。
G:图形进程。
Process name:进程的名称,如
python表示一个 Python 进程。GPU Memory Usage:进程使用的显存大小。
1.1环境配置
安装CUDA Driver:

安装CUDA:要求CUDA版本与GPU适配,根据设备情况选择合适版本(12.6)
下载cuDNN:官方文档:https://docs.nvidia.com/deeplearning/cudnn/latest/installation/windows.html
- 安装cuDNN:解压文件,将解压文件全部复制粘贴到cuda/v12.6中
下载TensorRT:解压将bin文件夹中的trtexec.exe文件复制到cuda/v12.6/bin文件夹中;将include目录中的所有头文件复制cuda/v12.6/include文件夹中;将lib文件夹所有 *.lib文件复制到cuda/v12.6/lib/x64文件夹;将lib文件夹中的所有 *.dll文件复制到cuda/v12.6/lib文件夹
安装TensorRT:
打开解压文件中的graphsurgeon文件夹,在当前路径下cmd打开终端,’pip install graphsurgeon-0.4.6-py2.py3-none-any.whl’;
打开解压文件中的onnx_graphsurgeon文件夹,在当前路径下cmd打开终端,’pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl’
打开解压文件中的uff文件夹,在当前路径下cmd打开终端,’pip install uff-0.6.9-py2.py3-none-any.whl’
打开python文件夹,选择对应的python版本,‘pip install’
验证:
import tensorrt as trt不报错就没错BUG:

(如果之前的步骤都有做 且lib文件夹下也有对应文件则)
添加环境变量:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib
1.2TensorRT介绍
2.构建阶段
2.1创建网络定义
2.2配置参数
2.3生成Engine
将onnx文件copy至D:\TensorRT-8.5.3.1\bin目录
trtexec --onnx=model.onnx --saveEngine=model.engine
Could not locate zlibwapi.dll. Please make sure it is in your library path!
2.4保存为模型文件
2.5释放资源
3.运行时阶段
3.1反序列化并创建Engine
3.2创建一个ExcutionContext
3.3为推理填充输入
3.4调用enqueueV2来执行推理
3.5释放资源
4.编译和运行
设备选型
1 |
|
在对应的硬件上查相应参数,需要高于模型的FLOPS和参数量,需要一定的冗余空间
因为pytorch的一般是FP32,边缘端一般是FP16或int8,所以按照pythorch上测出来的计算量来找硬件一般就行。
在算力冗余的情况下,也要看板子平台框架处理,作为AI算法来说,有时候需要反向提要求,就是根据板子来决定自己用什么模型,选型的时候,理论的算力要达到,再实际测一下(因为一般实际算力高于理论算力),大概率测一下帧率就可以了,


