
transformer
transform
概述
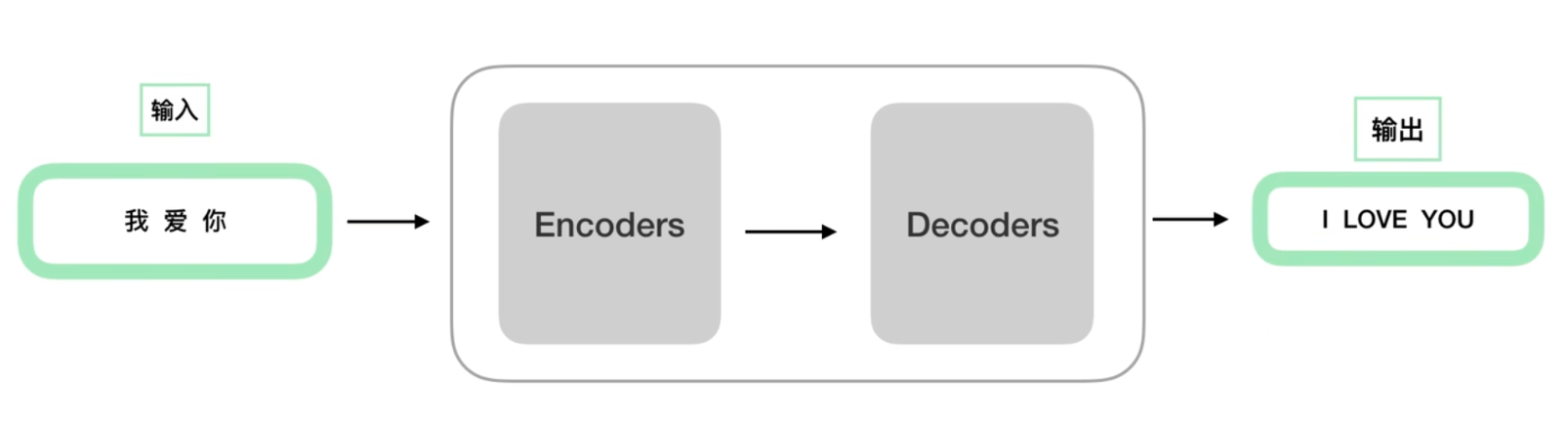
Encoders由N个Encoder组成,输入经由Encoders和Decoders编解码的过程,得到对应输出。
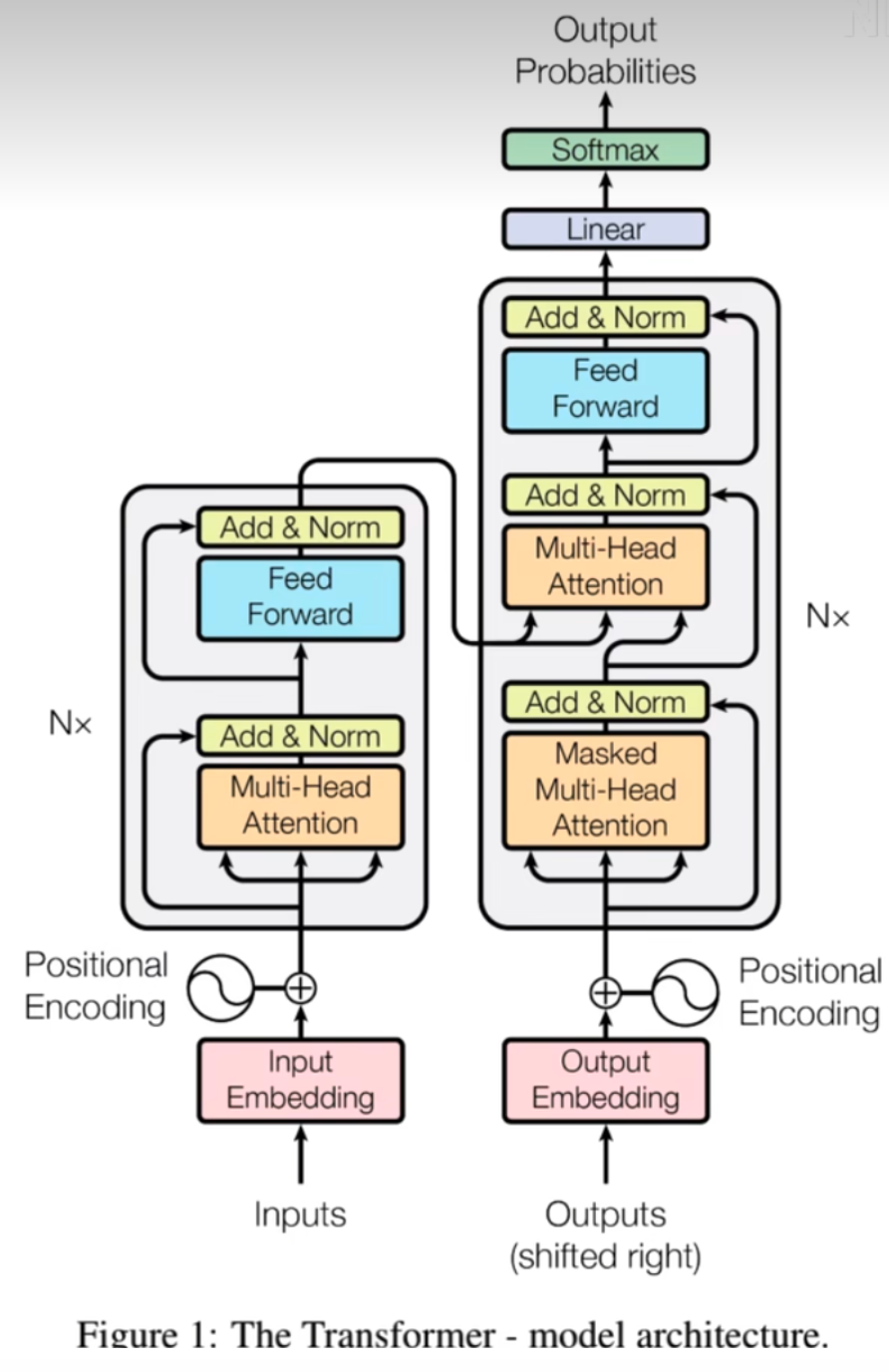
Encoder
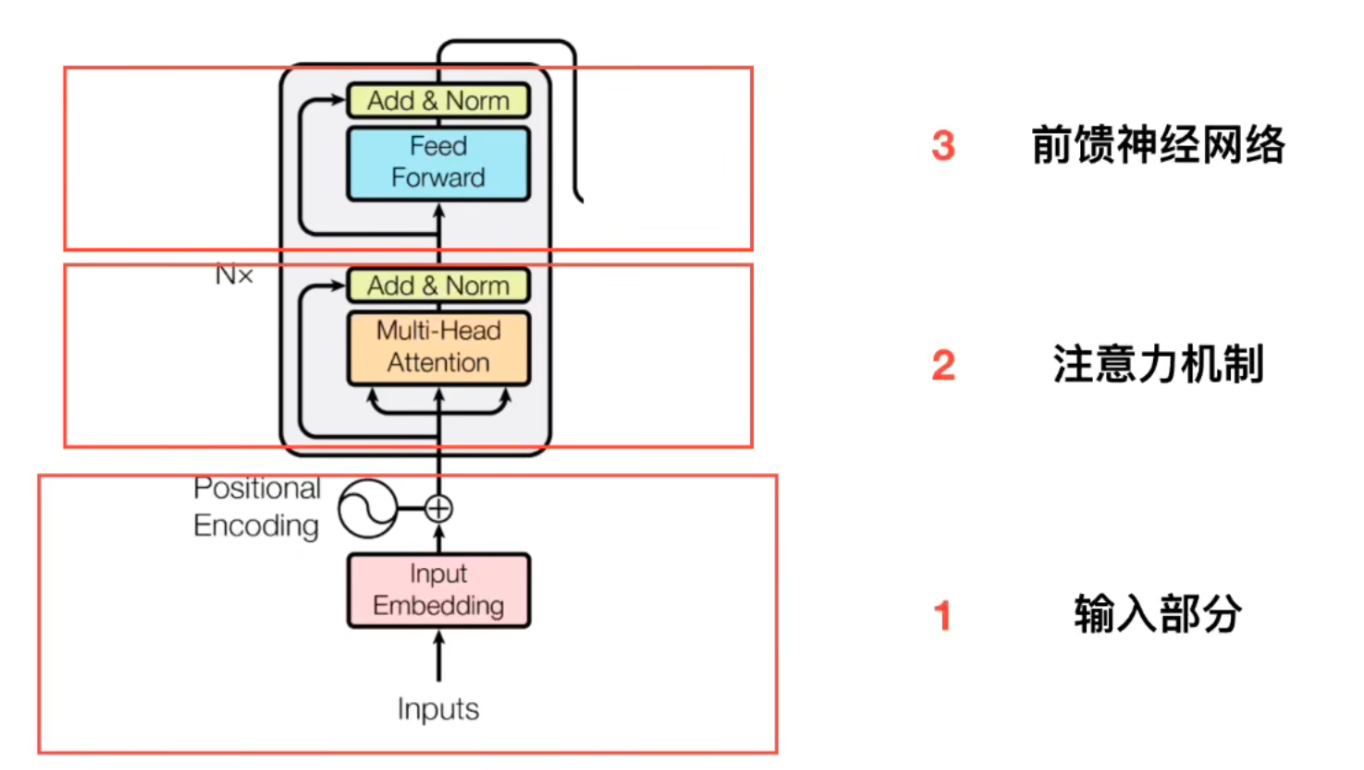
输入部分
Embedding
“embedding” 是一种将离散的输入数据(如单词、字符或符号)转换为连续的向量表示的技术。将输入的每个词(通常是词汇表中的索引)映射到一个固定大小的向量(比如300维或512维)。这些向量会作为模型的输入,传递给后续的编码器(Encoder)和解码器(Decoder)层。
位置编码
Transformer 模型中的注意力机制(Self-Attention)是并行计算的,它并不依赖于输入数据的顺序。因此,模型需要一种方法来捕捉输入序列中每个元素的顺序或位置信息,以便模型能够区分和理解数据的结构。
注意力机制
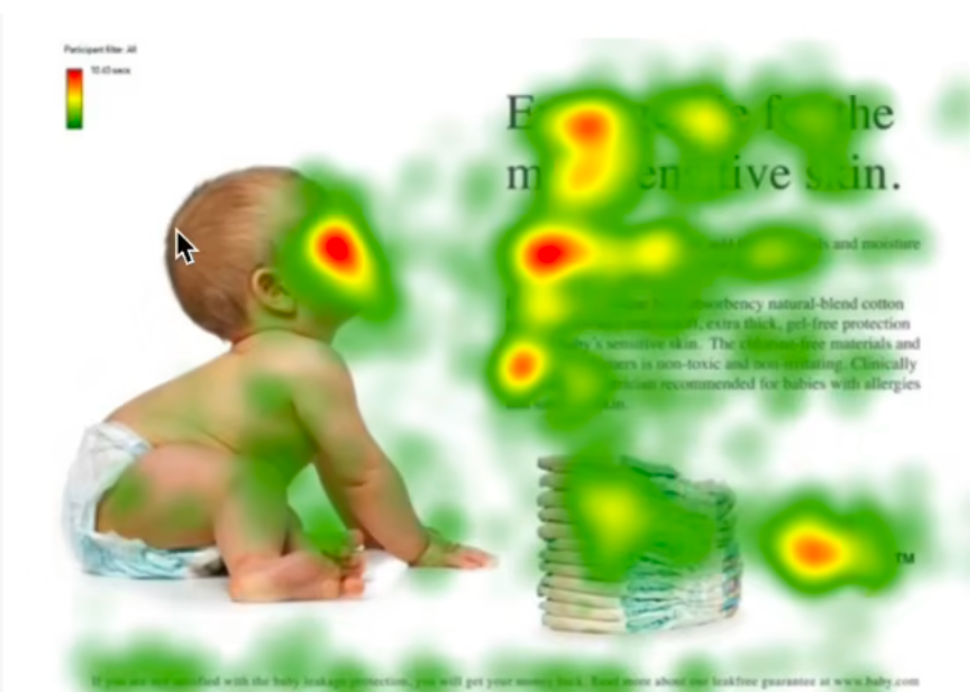
婴儿在干嘛?(颜色越深代表受的关注度越高)
计算公式
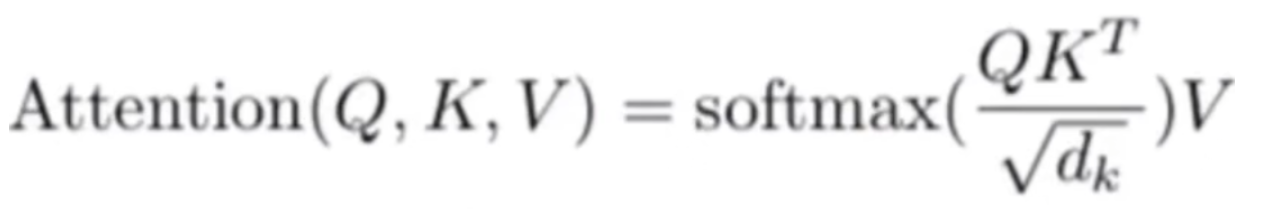
- qkv的生成
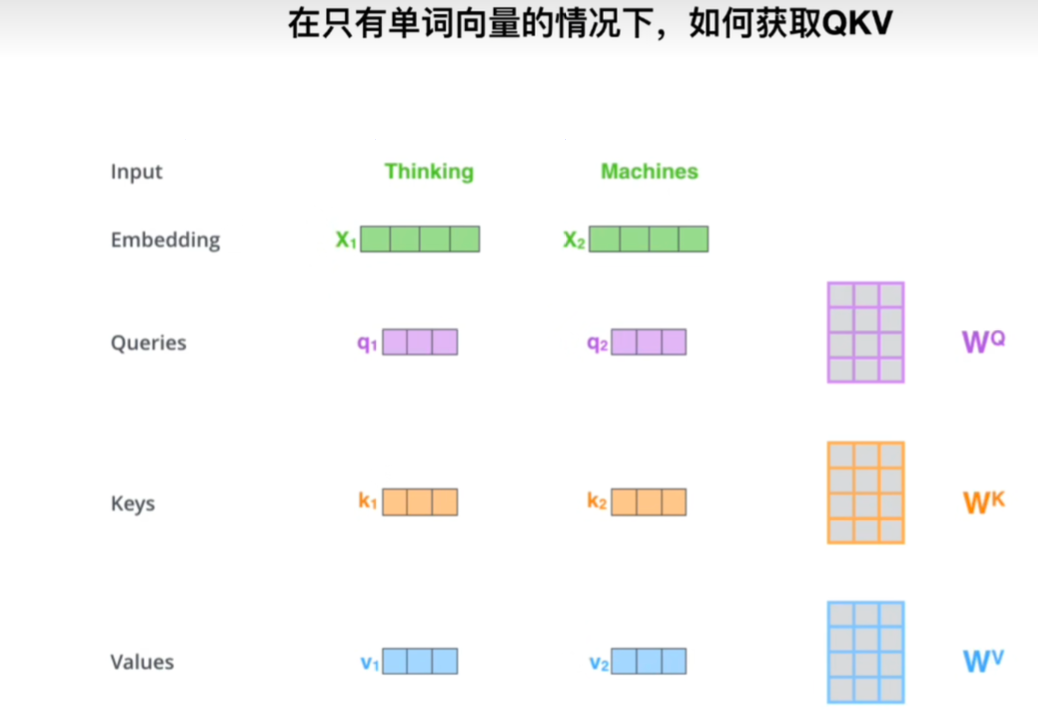
Query(Q):查询的向量,代表模型当前正在关注或感兴趣的部分。
Key(K):键向量,用于与 Query 进行匹配,以决定输入序列中哪些部分应该被关注。
Value(V):值向量,表示实际的信息内容,它会被加权并用于生成注意力输出。
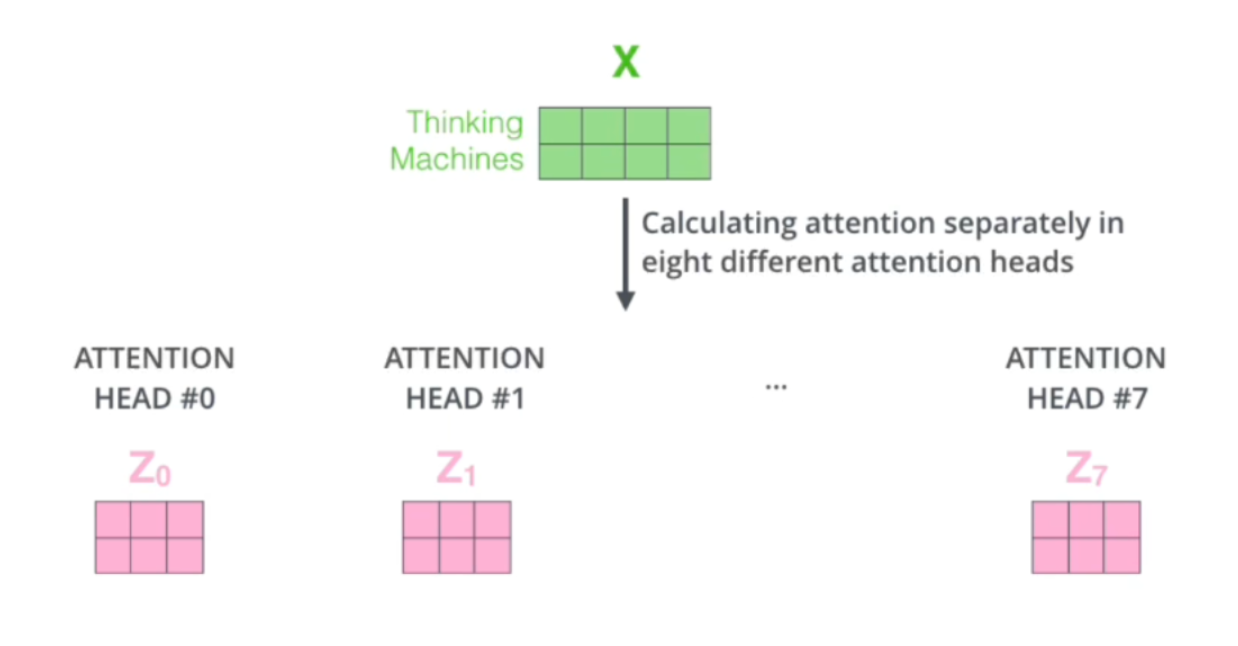
- 多头,其实就是其中对应的Wq,Wk,Wv不止一套,我们会同时使用多套权重进行qkv的生成,相当于每套权重对应的着重点不一样,关注的特征不一样,这样可以让transform更多的关注到不同特征空间
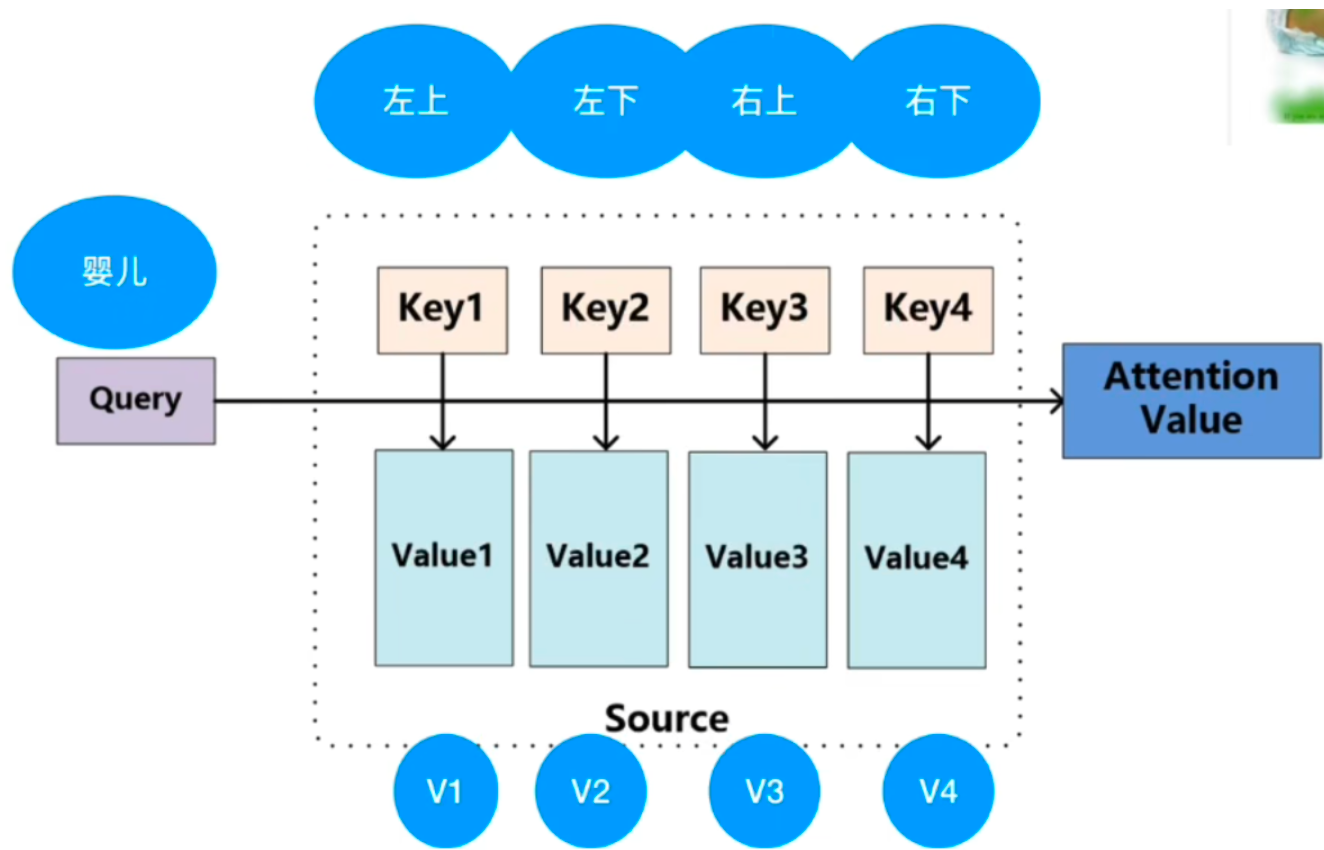
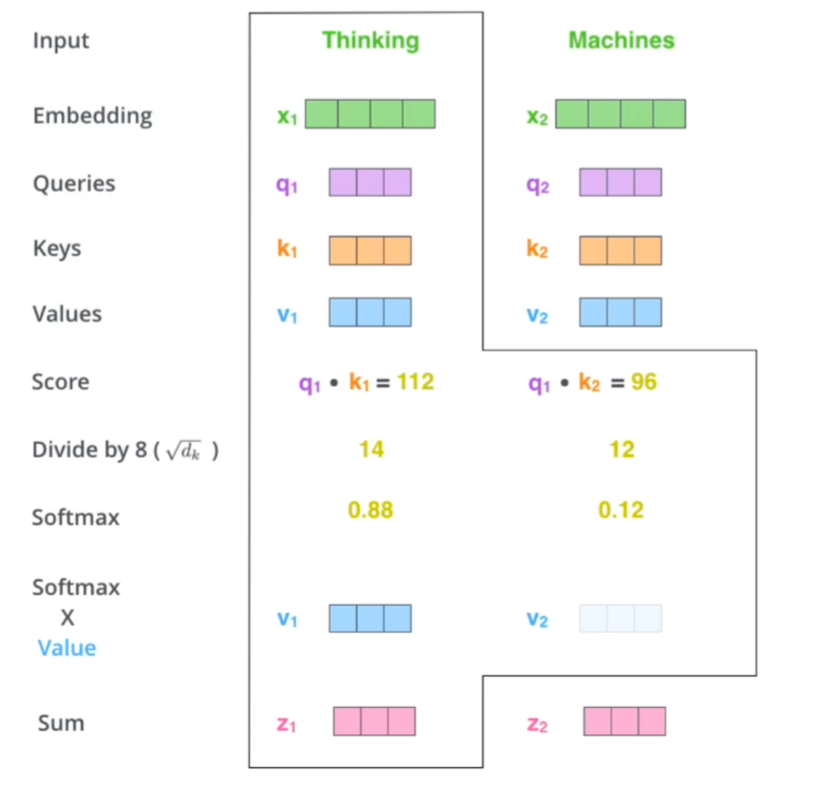
判断对那个区域更关注的时候,我们通过计算Q K的点乘得到相似度,然后经过softmax归一化得到注意力权重,权重对v向量进行加权求和得到新的表示。
- 多头注意力机制
残差和LayNorm
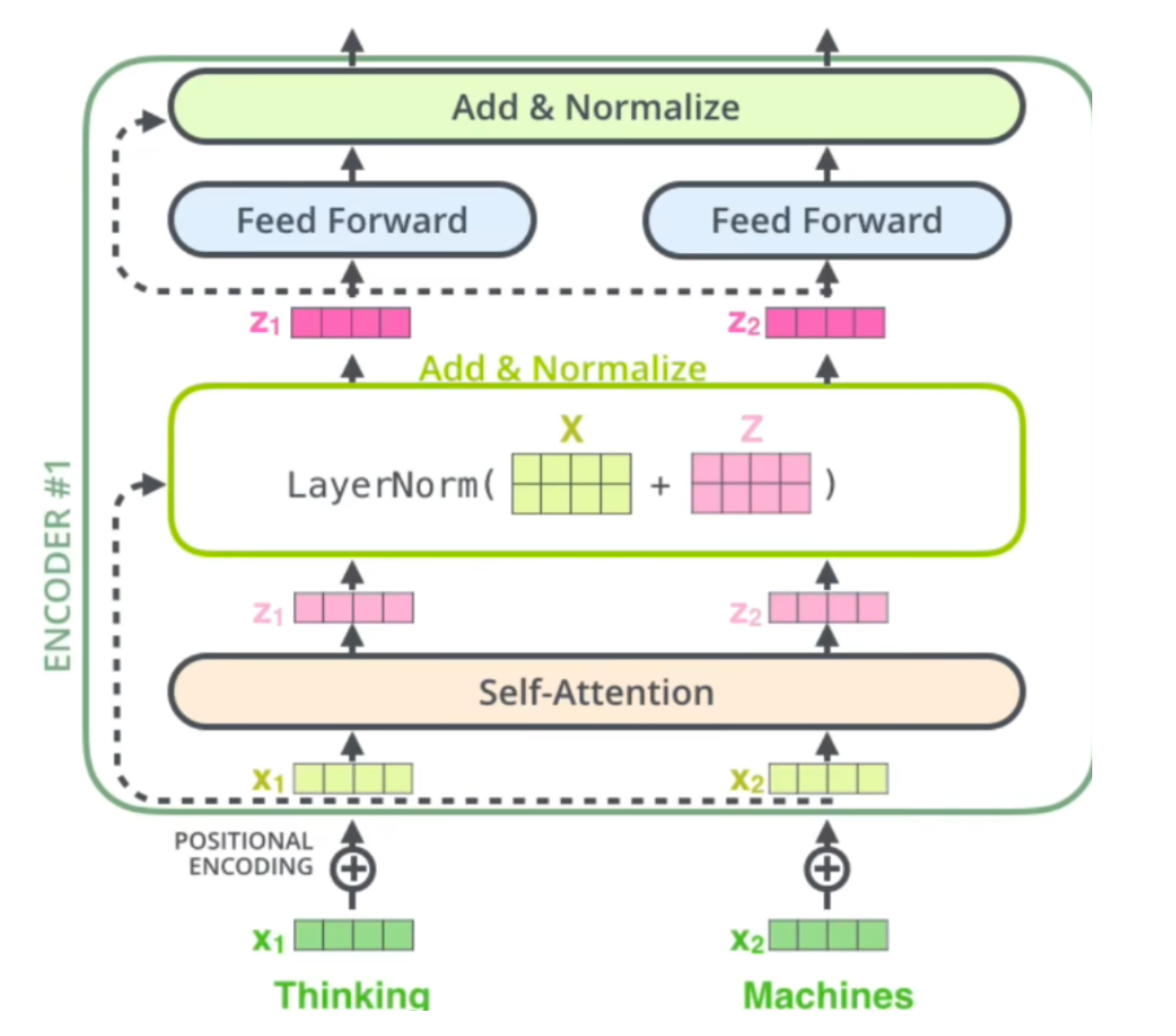
残差就体现在上面的x和z的对位相加
Layer Normalization
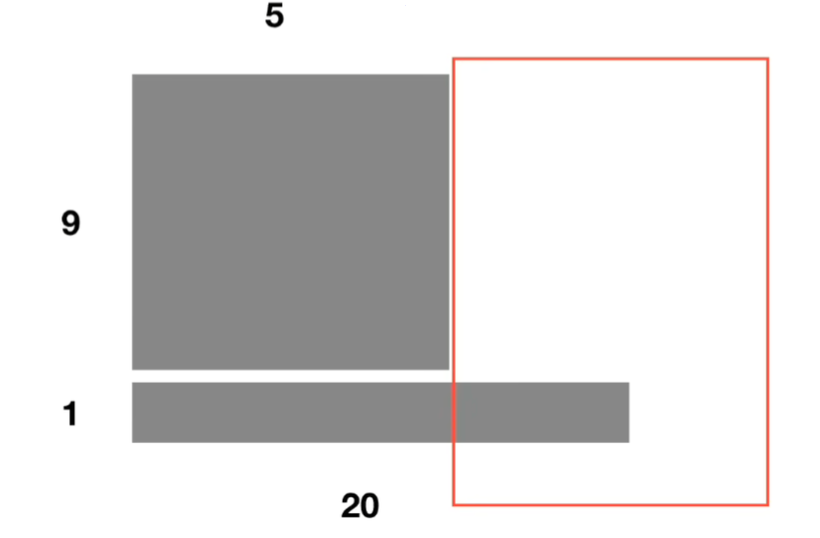

如果用BN前五个的均值方差是可以算的,但是后面的就没法计算了。而LN是单独对一个样本的所有单词去做缩放,(通俗来讲就是BN是把“我”和“今”一起计算均值方差,即认为我和今代表同一个语境,这显然是不合理的,而LN是把一句话作为一个语境,非官方)
Decoder
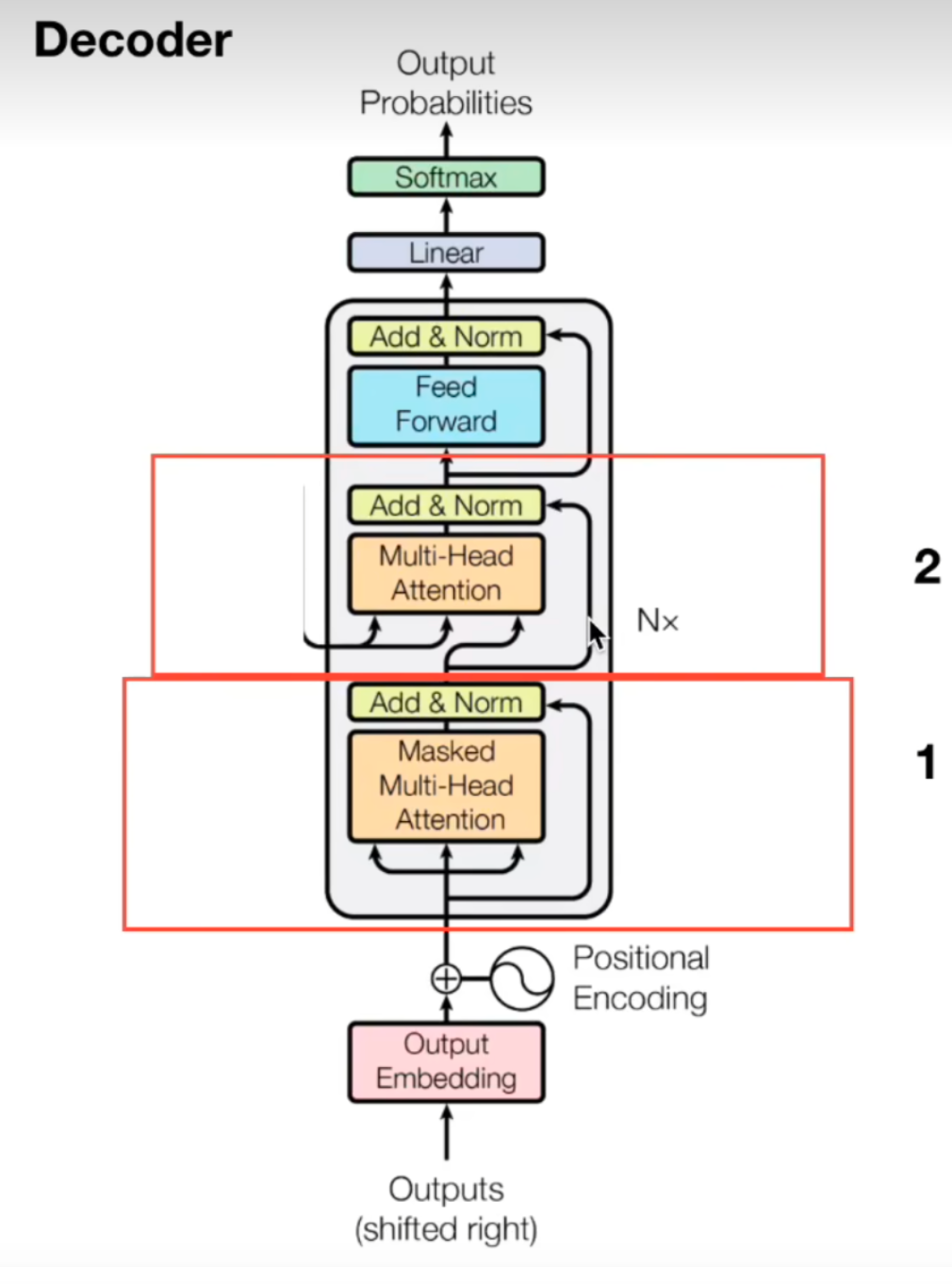
多头注意力机制中的mask
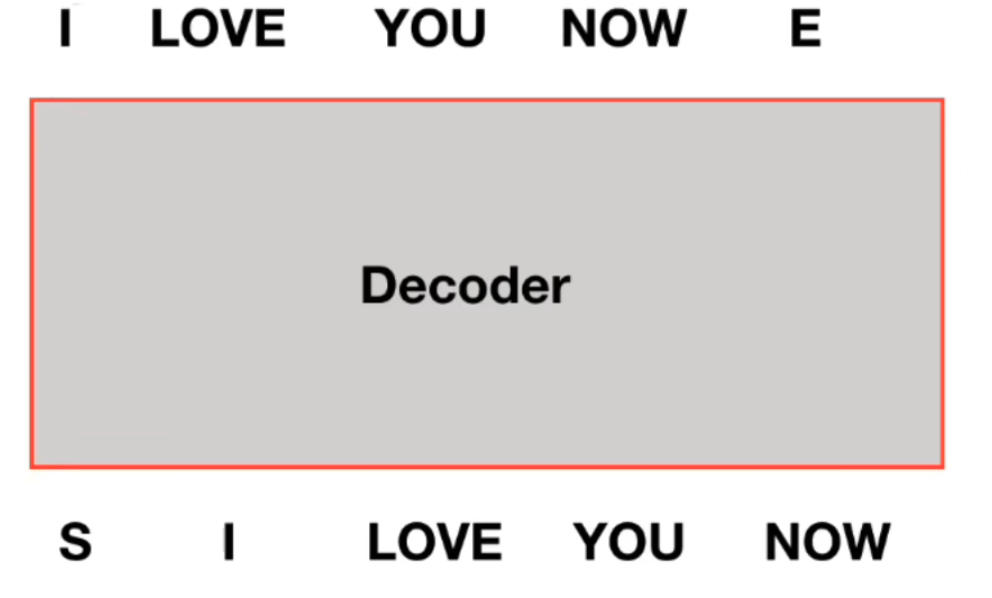
需要对当前单词和之后的单词做mask,在做预测人物的时候我们实际输入时我们是看不到后面的单词的,进行mask,保证模型训练和测试的一致性
交互
交互,encoder的输出是要和每一个decoder做交互的,这个层的作用是通过注意力机制,从编码器的输出中获取信息,以帮助解码器更好地生成目标序列。
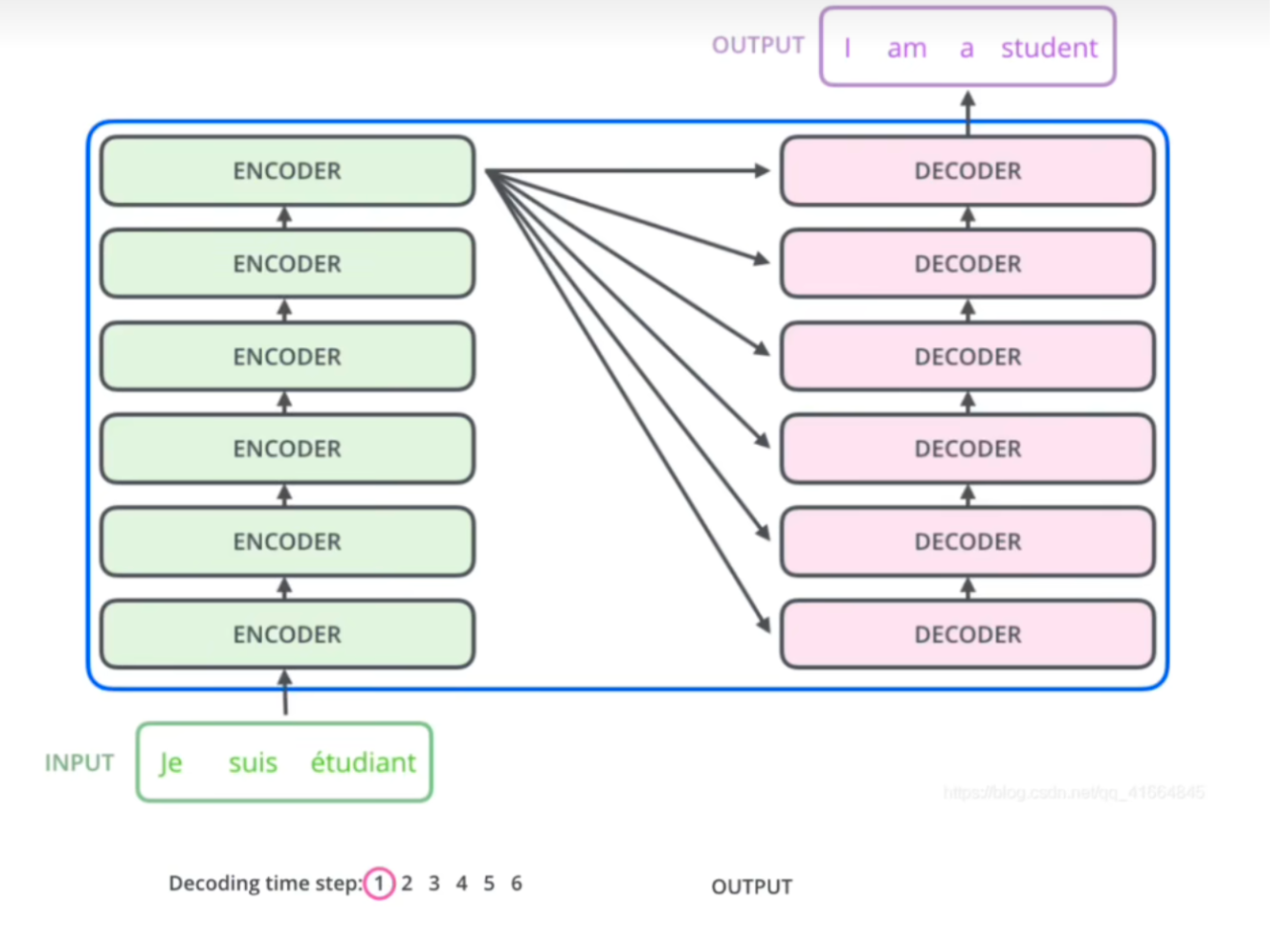
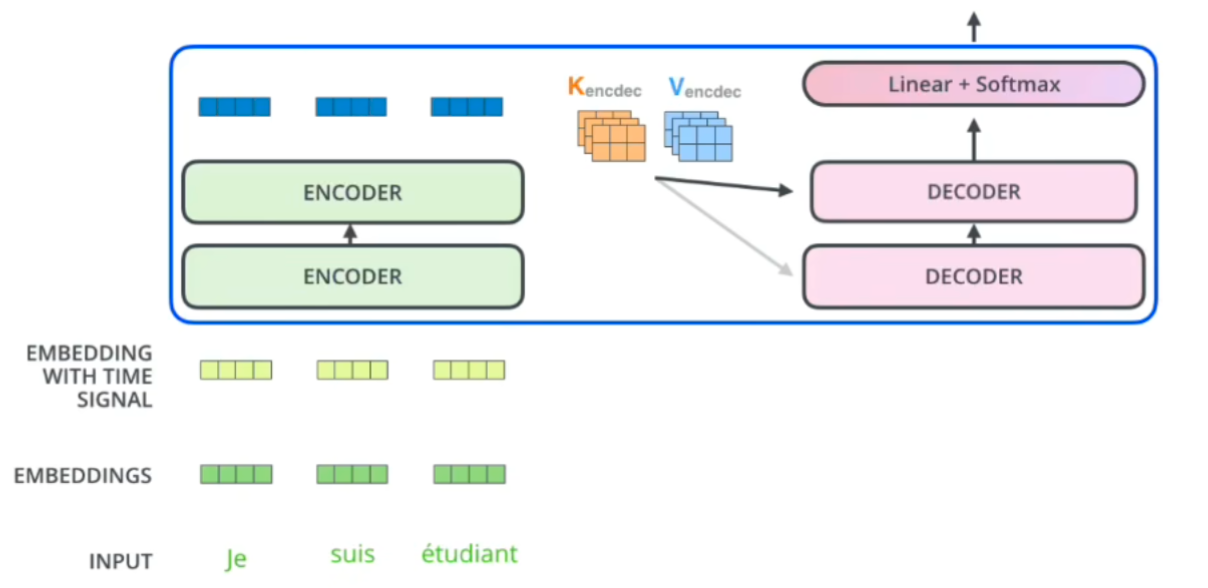
工作方式:
- 解码器会生成一个 Query 矩阵,这个矩阵与编码器的输出(即编码表示)生成的 Key 和 Value 矩阵进行点积,计算注意力分数。
- 这些注意力分数表示解码器在生成某个元素时应该关注编码器输出的哪些部分。
- 根据注意力分数对 Value 矩阵 进行加权,解码器得到了与输入序列相关的上下文信息,并将其用来帮助生成下一个元素。


