
提示词工程
提示词工程 prompt engineering
什么是提示词工程:我们在使用AI时,必须提出具体要求,AI才知道如何去完成。
但是我们下达的指令并不会直接进入AI模型,prompt engineering会对我们的输入进行处理转换成promprt,再输入到模型。这里的prompt可以理解一个把我们的指令进行复杂化的过程。(即赋予我们的指令更多的信息)
prompt engineering帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。
研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计、研发强大的工程技术,实现和大语言模型或其他生态工具的高效接轨。
大模型参数设置
- Temperature: 参数值越小,输出越确定,反之则越随机。
- Top_p: 参数值越大,输出越随机,反之则越确定。
- Max length: 输出文本最大长度。
- stop sequence: 输出文本结束符。
- Frequency penalty: 输出文本中重复词的惩罚系数。
- Presence penalty: 输出文本中新词的惩罚系数。
(与 temperature 和 top_p 一样,一般建议是改变 frequency penalty 和 presence penalty 其中一个参数就行,不要同时调整两个)
当使用openai的gpt-4或者gpt-3.5-turbo时。prompt:system,user,assistant
提示词要素
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
定义一个清楚的提示词
一个好的prompt应该像这样,但是我们平时使用GPT并不会吧问题问的这么详细。
1 | prompt = f""" |
提示技术
零样本提示
指令调整本质上是在通过指令描述的数据集上微调模型的概念。
少样本提示
使用零样本设置时,它们在更复杂的任务上仍然表现不佳。少样本提示可以作为一种技术,以启用上下文学习,我们在提示中提供演示以引导模型实现更好的性能。演示作为后续示例的条件,我们希望模型生成响应。
链式思考提示 COT
思维链提示时,这个过程需要手工制作有效且多样化的例子。这种手动工作可能会导致次优解决方案
自动思维链(Auto-cot)
Auto-CoT 主要由两个阶段组成:
- 阶段1:问题聚类:将给定问题划分为几个聚类
- 阶段2:演示抽样:从每组数组中选择一个具有代表性的问题,并使用带有简单启发式的 Zero-Shot-CoT 生成其推理链
自我一致性
自我一致性旨在“替换链式思维提示中使用的天真贪婪解码方法”。其想法是通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高 CoT 提示在涉及算术和常识推理的任务中的性能。
生成知识提示
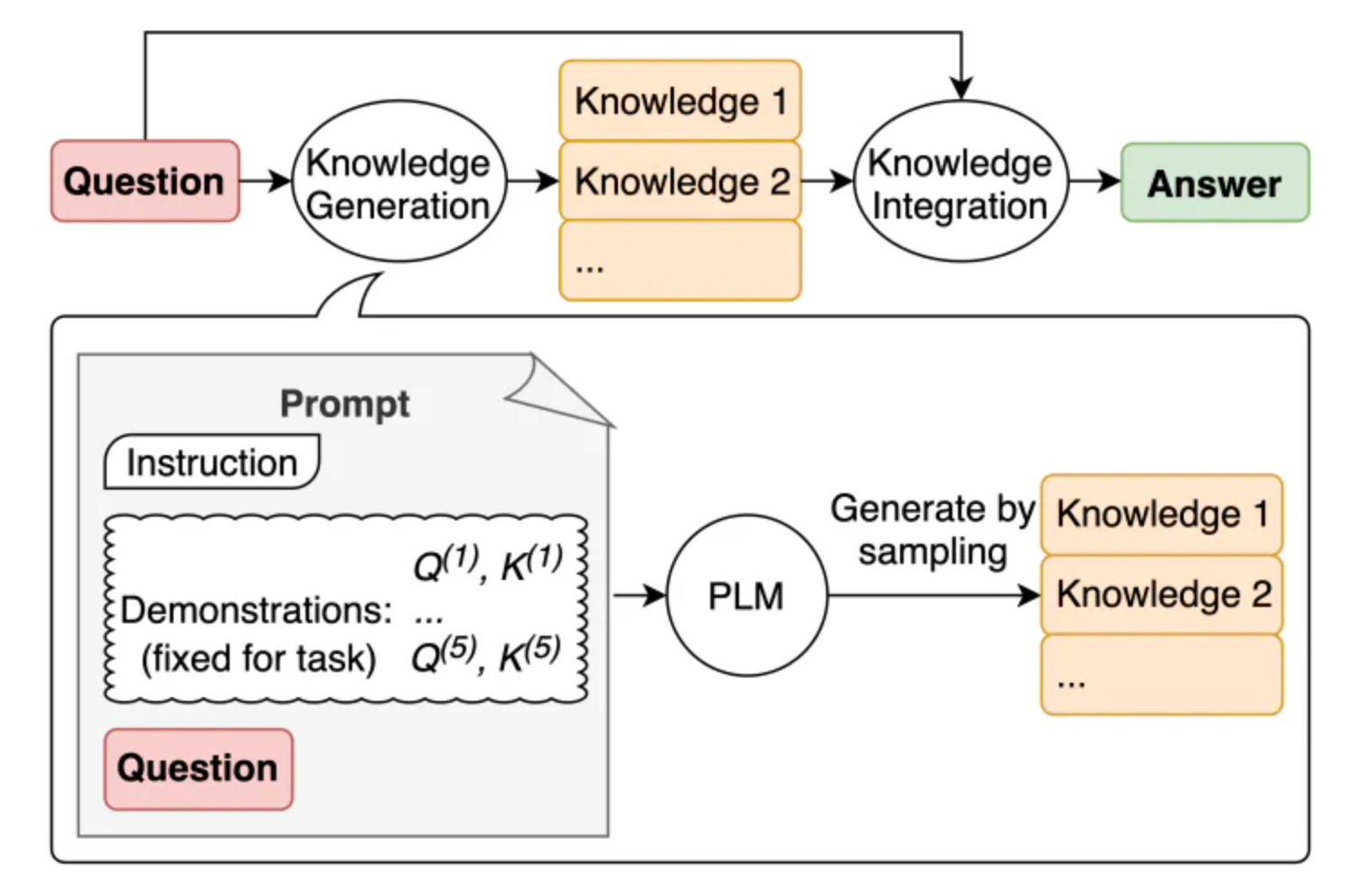
链式提示 prompt chaining
将任务分解为许多子任务。 确定子任务后,将子任务的提示词提供给语言模型,得到的结果作为新的提示词的一部分。 这就是所谓的链式提示(prompt chaining),一个任务被分解为多个子任务,根据子任务创建一系列提示操作。
示例
文档问答:
提示链可以用于不同的场景,这些场景可能涉及多个操作或转换。例如,LLM 的一个常见用途是根据大型文本文档回答问题。想要更好阅读大文本文档,可以设计两个不同的提示,第一个提示负责提取相关引文以回答问题,第二个提示则以引文和原始文档为输入来回答给定的问题。换句话说,可以创建两个不同的提示来执行根据文档回答问题的任务。
思维树ToT:
Tree of Thoughts 是一种提示技术,它允许 LLM 思考问题,并生成一系列步骤,然后根据步骤生成答案。
TOT维护着一颗思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LM能够自己对严谨的推理过程的中间思维进行评估。LM将生成及评估思维的能力与搜索苏阿法相结合,在系统性探索思维的时候可以向前验证和回溯。
ToT框架原理如下: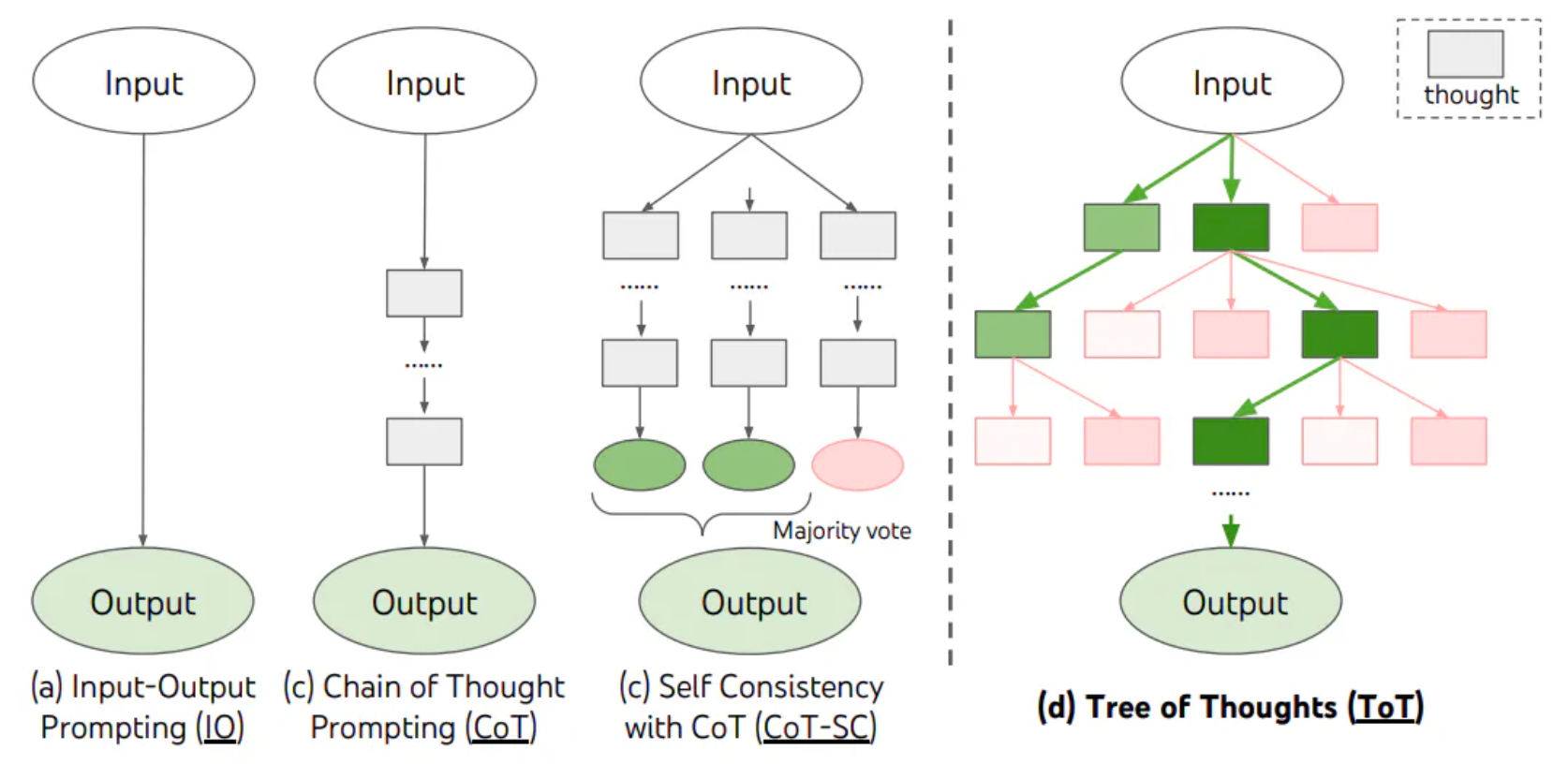
检索增强生成RAG
基于语言模型构建一个系统,访问外部知识源
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。


