模型优化(性能)
https://pytorch.org/tutorials/beginner/profiler.html
剪枝和蒸馏不可控,实际生产中一般使用量化。
部署时需要根据设备,考虑模型大小与模型计算量
剪枝
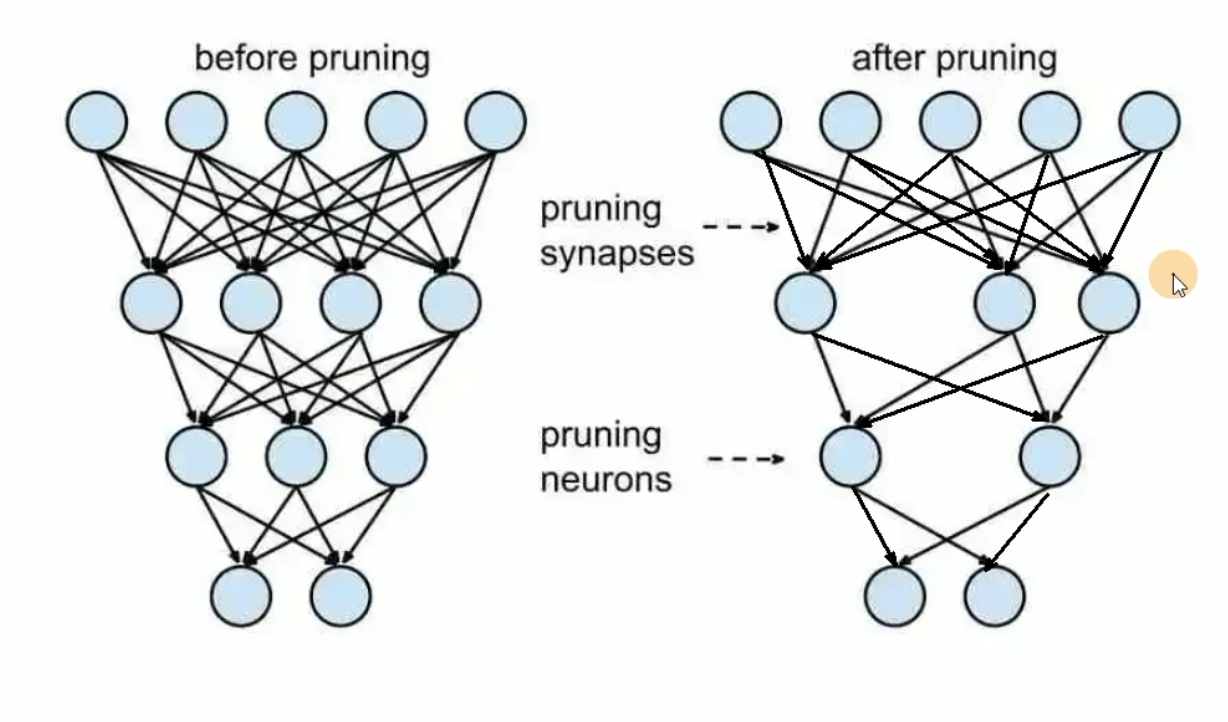
连接变稀疏了,计算量减少,直接使网络中的部分神经元失活(将参数置为0,不再参与运算可以加速模型的计算),但依赖于特定算法库或硬件平台的支持。
模型深层拿到的是语义特征,模型浅层拿到的是边缘特征。
1
2
3
4
5
| import torch.nn.utils.prune as prune
conv = model.conv1
prune.random_unstructured(conv, name="weight", amount=0.3)
prune.random_unstructured(conv, name="bias", amount=0.3)
|
全局剪枝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| model = LeNet()
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.2,
)
|
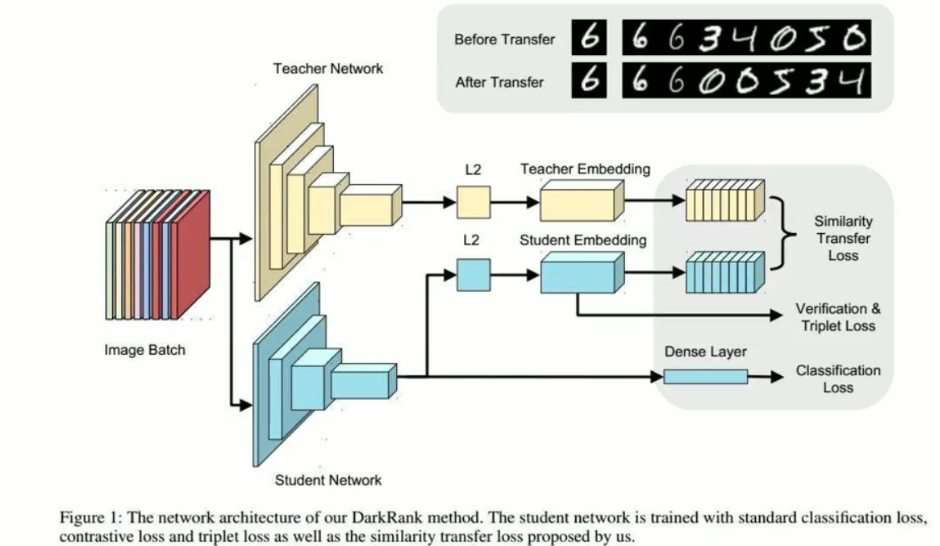
蒸馏
准备好一个训练好的较大的模型(teacher_net),其次准备一个未训练的较小的模型(student_net)。知识蒸馏的目的,就是让student_net从teacher_net中学习到teacher_net的知识,从而达到模型压缩的目的。
蒸馏温度T:
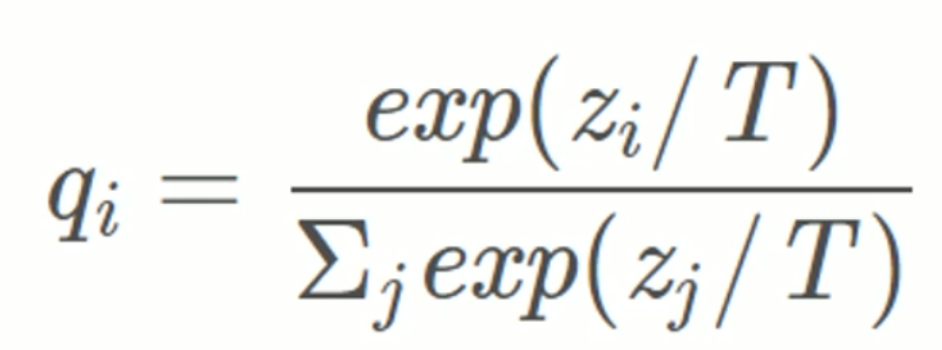
应用场景:
模型压缩|优化训练,防止过拟合|少样本、零样本学习|无限大、无监督数据集的数据挖掘
soft labels:包含当前特征分布的
hard labels:
学习特征提取方法
缺点:要训练两次,资源消耗大;student_net的选择也要根据任务选择体量。
(信息论)
特征损失:
交叉熵:
相对熵:还原特征分布
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
import torch
import torch.nn as nn
import numpy as np
from torch.nn import CrossEntropyLoss
from torch.utils.data import TensorDataset,DataLoader,SequentialSampler
class model(nn.Module):
def __init__(self,input_dim,hidden_dim,output_dim):
super(model,self).__init__()
self.layer1 = nn.LSTM(input_dim,hidden_dim,output_dim,batch_first = True)
self.layer2 = nn.Linear(hidden_dim,output_dim)
def forward(self,inputs):
layer1_output,layer1_hidden = self.layer1(inputs)
layer2_output = self.layer2(layer1_output)
layer2_output = layer2_output[:,-1,:]
return layer2_output
model_student = model(input_dim = 2,hidden_dim = 8,output_dim = 4)
model_teacher = model(input_dim = 2,hidden_dim = 16,output_dim = 4)
inputs = torch.randn(4,6,2)
true_label = torch.tensor([0,1,0,0])
dataset = TensorDataset(inputs,true_label)
sampler = SequentialSampler(inputs)
dataloader = DataLoader(dataset = dataset,sampler = sampler,batch_size = 2)
loss_fun = CrossEntropyLoss()
criterion = nn.KLDivLoss(reduction='batchmean')
optimizer = torch.optim.SGD(model_student.parameters(),lr = 0.1,momentum = 0.9)
for step,batch in enumerate(dataloader):
inputs = batch[0]
labels = batch[1]
output_student = model_student(inputs)
output_teacher = model_teacher(inputs)
loss_hard = loss_fun(output_student,labels)
loss_soft = criterion(output_student,output_teacher)
loss = 0.9*loss_soft + 0.1*loss_hard
print(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
|
bug:KL函数的更新
参考:link:[https://blog.csdn.net/weixin_45084253/article/details/124347676?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522172119759616800175769945%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=172119759616800175769945&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-124347676-null-null.142^v100^pc_search_result_base7&utm_term=userwaring%3Areduce%EF%BC%9A%E2%80%98mean%E2%80%99%20divides&spm=1018.2226.3001.4187]
KL散度:
量化(主流)
深度学习因其计算复杂度或参数冗余,在一些场景熵和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署。
学术界还提出了一个混合精度:重要的参数保持高精度,其他的选用低精度。
1
2
3
4
5
6
7
8
9
|
from torch.cuda import amp
scaler = amp.GradScaler(enabled=cuda)
···
scaler.scale(loss).backward()
|
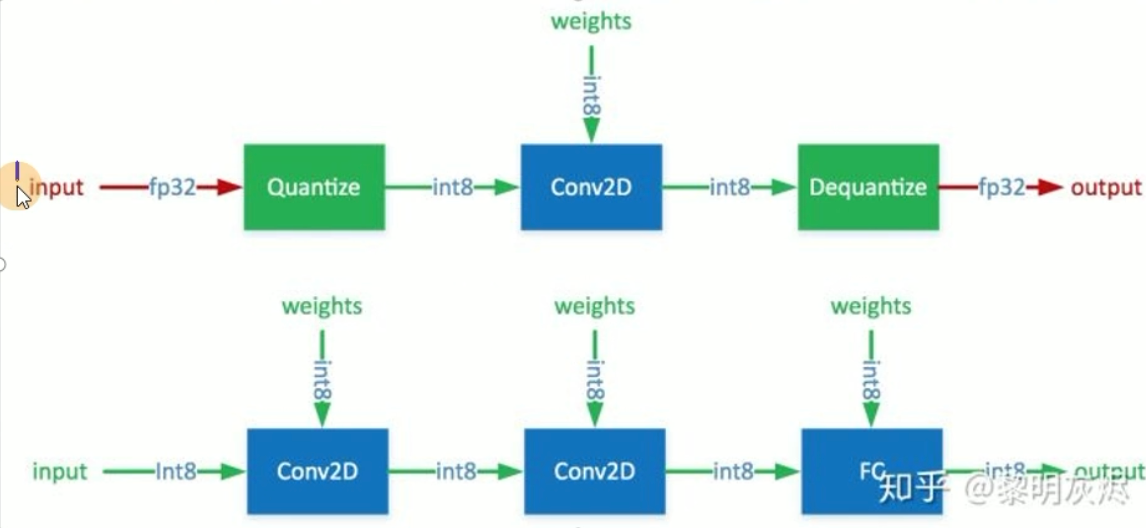

减小模型体积
减少模型计算量
量化不像剪枝和蒸馏需要依靠经验来确定,而是需要根据模型结构、数据分布、硬件资源等条件进行量化。
pytorch的量化还处于研究阶段,
量化是指将数据规范到可度量的范围内。
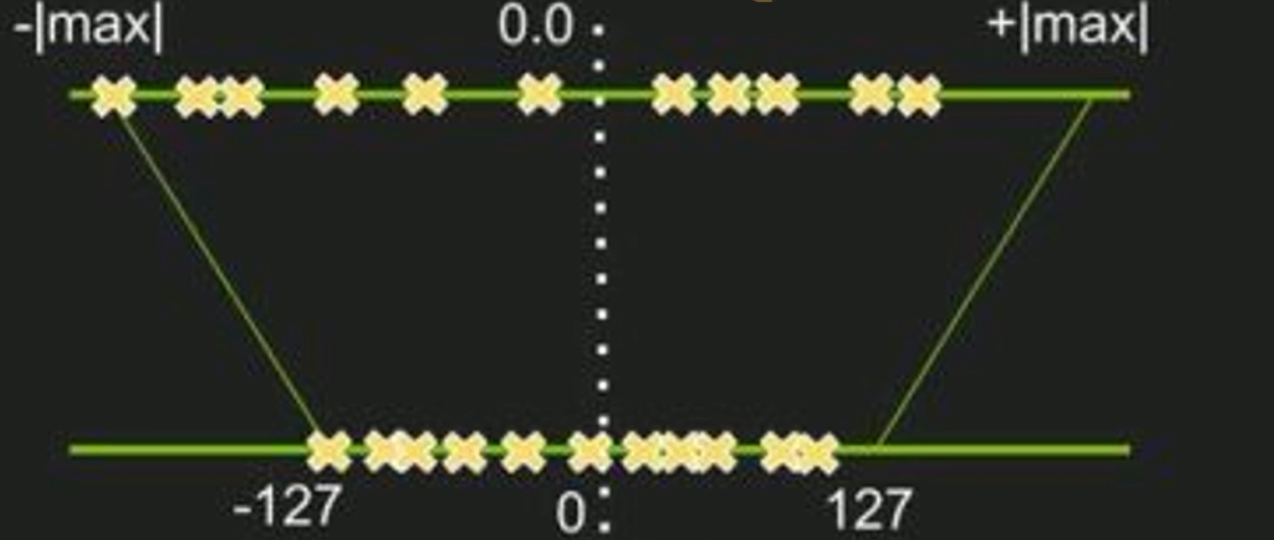
量化分为静态量化和动态量化,静态量化是指在训练过程中对模型进行量化,动态量化是指在运行过程中对模型进行量化。静态量化可以减少模型体积,但需要训练时间长,动态量化可以减少计算量,但需要实时量化,且精度可能会降低。
- 张量量化
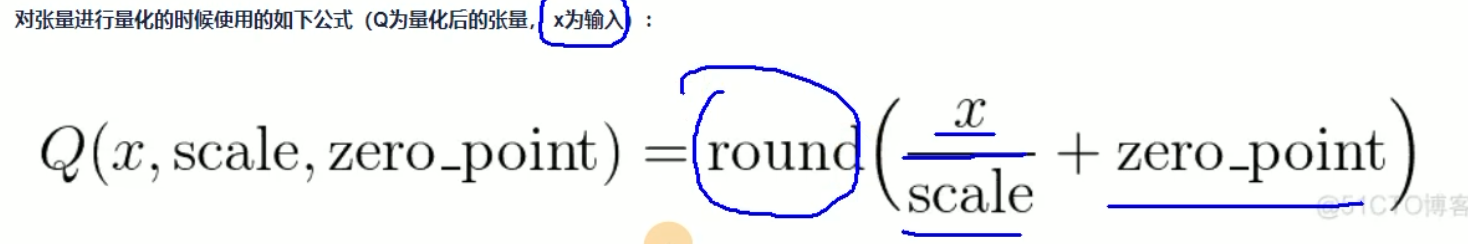
1
2
3
4
5
| tench.quantize_per_tensor(scale, zero_point, dtype)
scale: 缩放因子,用于将原始数据映射到[-1,1]区间
zero_point: 零点,用于将原始数据映射到[-1,1]区间
dtype: 输出数据的类型(torch.quint8, torch.qint8, torch.qint32)
|
- 张量反量化
1
| dequantized_tensor = tensor.dequantize()
|
pytorch静态量化官方文档 测试阶段,只支持cpu,且对硬件有要求。
量化依赖平台和设备,如GPU、FPGA、NPU等,需要根据硬件特性和模型特点进行量化。