
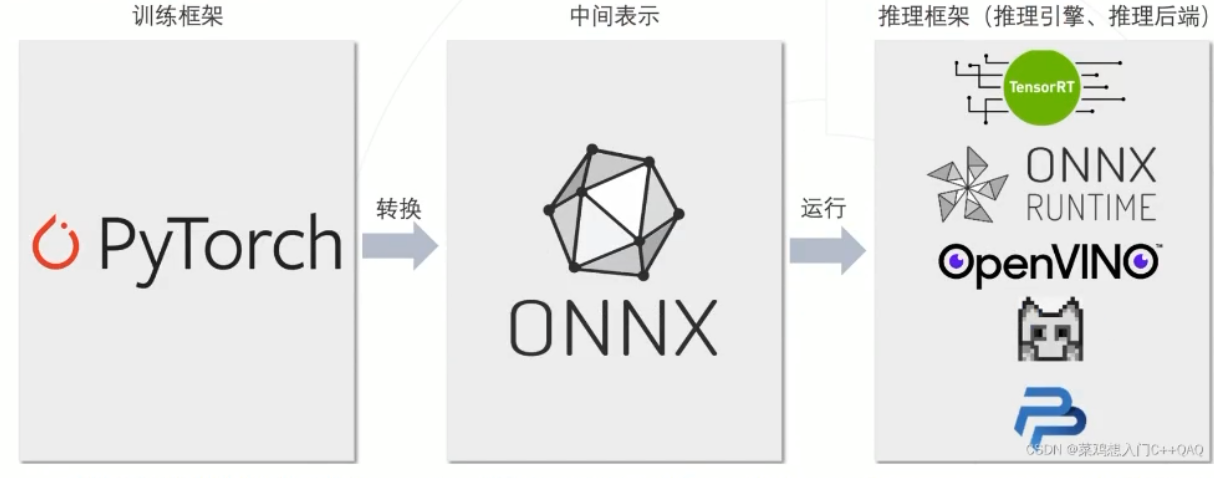
模型打包
模型打包
目前自己所用的框架为pytorch(python版本的torch),需要打包好训练好的AI模型(网络结构+网络参数),放到其他设备上运行。
LibTorch也是一个部署时候用的推理框架 c++/java 版本
TorchScript:torch自己的打包工具
torch保存模型的方式:
1 只保存模型参数(权重文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
# torch.save(model.state_dict(), 'model.pth')
import torch
from torchvision.models import resnet18
model = resnet18()
torch.save(model.state_dict(), 'model.pth') # 只保存权重
###
import torch
import torchvision.models as models
net = models.resnet18()
net.load_state_dict(torch.load("model.pth"))
input = torch.randn(1, 3, 224, 224)
net(input)
# TypeError: 'collections.OrderedDict' object is not callable
2 同时保存网络结构和模型参数
- torch.jit模型
1
2
3
4
5
6
7
8
9
10
net = models.resnet18(weights=ResNet18_Weights)# pretrained=True 之前版本的使用方法
# 打包前需要调用eval
net.eval()
# 定义模型输入的形状(预留输入接口)
input = torch.randn(1,3,244,244)
track_model = torch.jit.trace(net,input)
track_model.save('resnet18.pt')
#torch.jit.load('resnet18.pt')
- torch.save(model, ‘model.pkl’)
1 | # torch.save(model.state_dict(), 'model.pth') |
1 | net = models.resnet18(weights=ResNet18_Weights)# pretrained=True 之前版本的使用方法 |
保存文件的大小
- torch.save
通用性: torch.save 是一个非常通用的函数,可以用来保存任何可被序列化的 Python 对象,包括但不限于 PyTorch 模型的参数(state_dict)、整个模型实例、优化器状态等。
保存内容: 当直接保存整个模型实例 (torch.save(model, ‘model.pt’)) 时,它会保存模型的结构以及所有参数。如果只保存模型的状态字典 (torch.save(model.state_dict(), ‘model_state_dict.pt’)),则仅保存模型参数,不包括模型的定义。
使用场景: 适用于模型训练过程中参数的快照保存,或者在相同环境(如相同的Python版本和库版本)之间迁移模型。 - torch.jit.save
针对TorchScript: torch.jit.save 主要用于保存经过脚本化(scripting)或跟踪(tracing)的模型,即 TorchScript 模型。TorchScript 是 PyTorch 的一种表示形式,它可以将 PyTorch 模型转换为静态图的形式,这样模型可以在没有Python依赖的环境中运行,例如在C++或JavaScript中。
优化部署: 保存的 .pt 文件包含了一个独立于源代码和Python环境的模型,这使得模型能够在生产环境中更高效、安全地部署。
跨平台打包
- ONNX
onnx(open neural network exchange) 是一种开放格式,旨在表示机器学习模型。通俗来讲其表示一种统一的中间结构。
1 | # Input to the model |
跨平台一定会造型模型精度变化,所以需要在打包后对模型进行验证
实际操作一般不会去做验证,因为现在模型框架已经做的很完善了,如果存在巨大的精度误差也是onnx框架的问题,我们是不好解决的。
- 验证onnx模型框架的正确性
1
2
3
4
5import onnx
onnx_model = onnx.load("super_resolution.onnx")
onnx.checker.check_model(onnx_model)
# 没有输出即验证成功 - 验证onnx模型精度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import onnxruntime
ort_session = onnxruntime.InferenceSession("super_resolution.onnx", providers=["CPUExecutionProvider"])# 导入模型及验证设备 一般是在cpu上进行验证
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)
# compare ONNX Runtime and PyTorch results
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)# 对比两个数组的值在一定精度误差范围内是否相等 如果不相等则抛出异常 atol小数点后几位
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
模型可视化
Netron
https://netron.app/
直接将训练好的模型拖入网页即可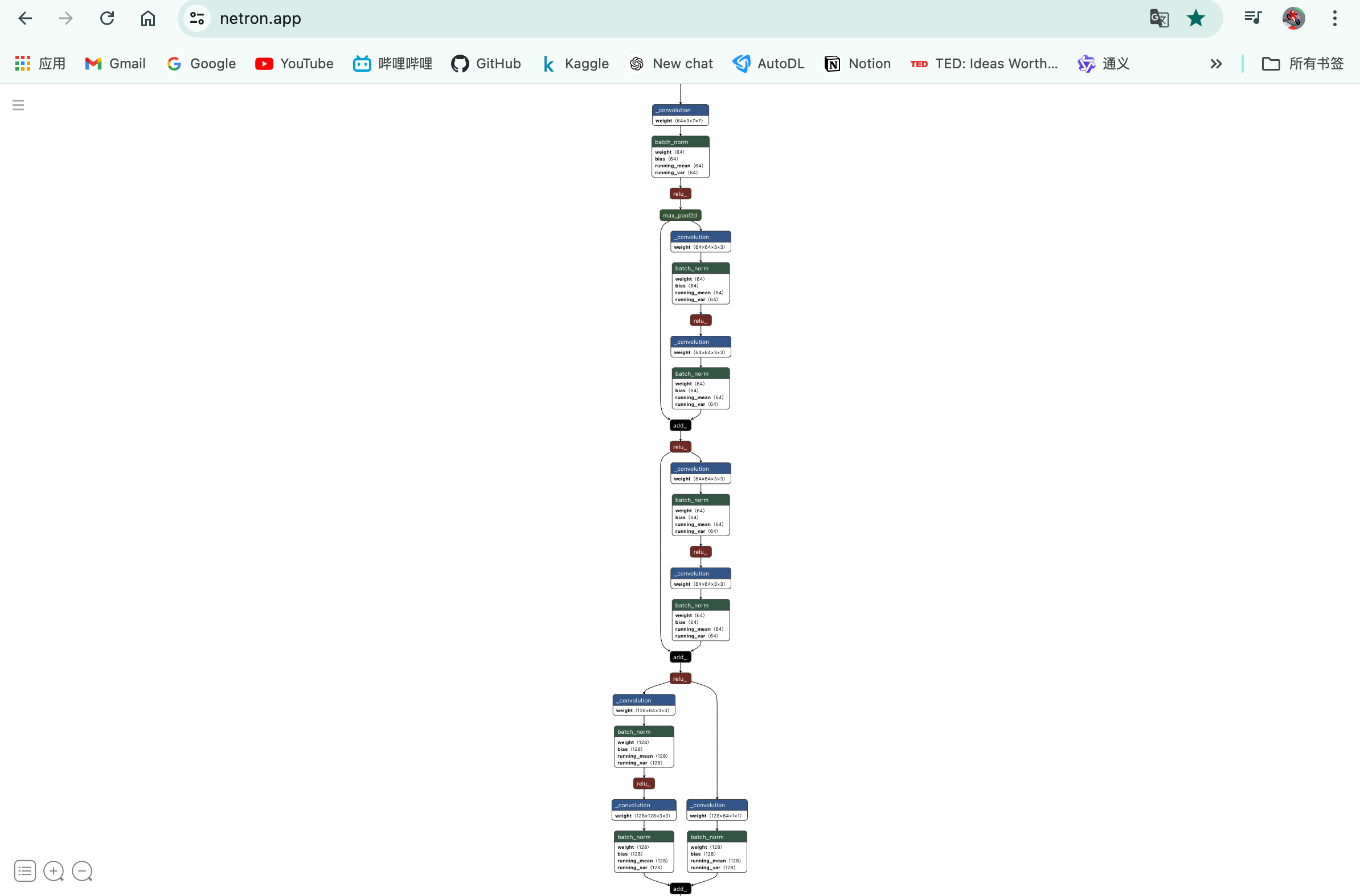
torchsummary
1
2
3# 模型可视化
from torchsummary import summary
summary(net, input_size=(3, 128, 128))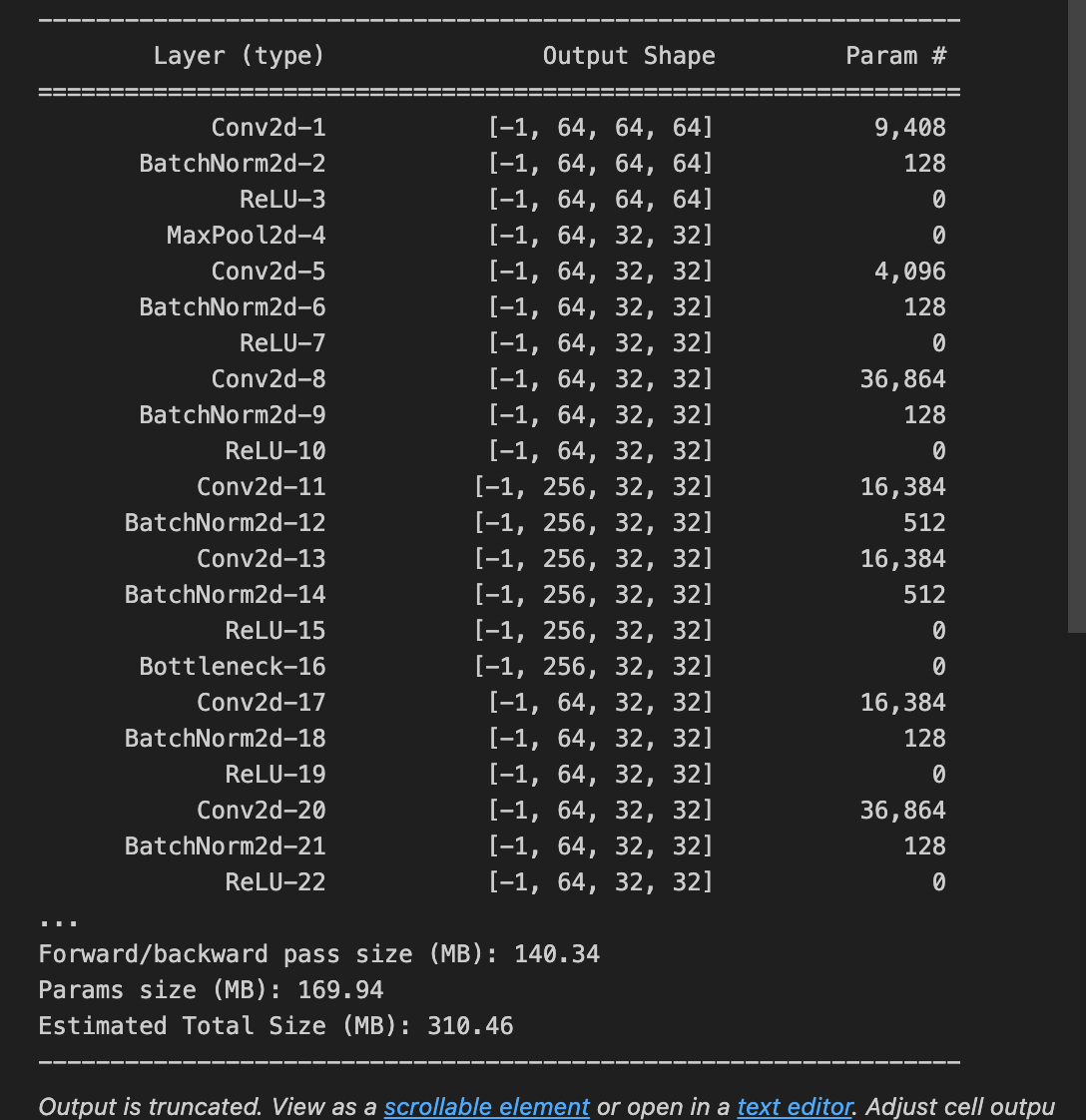
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 廾匸!


