
图像分割
图像分割
图像分割是图像分类和对象检测的高级推演,也是一套独特的计算机视觉功能。
图像分类将类型标签应用于整个图像。例如,可以训练一个简单的图像分类模型,将车辆图片分为“汽车”和“卡车”。传统的图像分类模型并不单独处理单个图像特征,因此复杂程度有限。
对象检测将图像分类与对象定位相结合,生成对象所在的矩形区域(称为“边界框”);对象检测模型可以指出图像中可以找到汽车或卡车的位置,而不是仅仅将车辆图像标记为“汽车”或“卡车”。虽然对象检测可以对图像中的多个元素进行分类,并估算出每个元素的宽度和高度,但它无法识别精确的边界或形状。这就限制了传统对象检测模型对边界框重叠的精密对象进行划分的能力。
图像分割再像素级别处理视觉数据,使用各种技术将单个像素标注为属于特定类别或实例。“经典”图像分割技术通过分析每个像素的固有特性(称为“启发式”)(如颜色和强度)来确定标注内容,而深度学习模型则采用复杂的神经网络来进行复杂的模式识别。这种标注的输出是分割掩码,代表图像中每个类别(通常对应不同对象、特征或区域)的具体像素边界和形状
https://www.ibm.com/cn-zh/topics/image-segmentation
普通分割
将不同物体的像素区域区分开,如前景和后景分割开。

语义类
每种类型的图像分割任务之间的区别在于他们如何处理语义类别:指定像素可能被确定属于的具体类别。
用计算机视觉的术语来说,有两种类型的语义类别。每种方法都适合使用不同的技术进行准确有效的分割。Things是具有特征形状的对象类别,如”汽车”、“树”或“人”。它们在大小上的差异相对较小,并且有不同于thing本身的构成部分:例如,所有汽车都有轮子,但轮子不是汽车。
Stuff是指形状无定形且大小变化很大的语义类别,例如“天空”、“水”或“草”。通常,stuff是没有明确定义的,可计数的单个实例。与things不同,stuff没有不同的部分;一片草叶和一片草地都是“草”在某些图像条件下,某些类别既可以是things,也可以是stuff。例如,一大群人可以被解释为多个“人”,每个人都是形状独特、可数的things,或者是单个、形状不定的“人群”
虽然大多数对象检测工作主要集中在thing类上,但重要的是要考虑到stuff(天空、墙壁、地板、地面)构成了文明大部分的视觉环境。stuff是识别things的基本数据点,反之亦然:道路上的金属物通常是汽车;
语义分割
语义分割时最简单的图像分割类型。语义分割模型为每个像素分配一个语义类别,但不输出任何其他的上下文或信息(如对象)在普通分割的基础上,分类出每一块儿区域的语义(即这块儿区域是什么物体),如把画面中的所有物体都指出他的类别。

实例分割
实例分割颠倒了语义分割的有限顺序:语义分割算法只预测每个像素的语义分类(不考虑单个实例),而实例分割则精确划分每个独立对象实例的形状。
在语义分割的基础上,给每个物体编号,如这个是该画面中的狗A,那个是画面中的狗B
实例分割算法通常采用两阶段或单词方法来解决问题。两阶段模型,例如基于区域的卷积神经网络(R-CNN),会执行传统的对象检测,为每个提议的实例生成边界框,然后再每个边界框内执行更精细的分割和分类。单词模型。如YOLO,通过同时执行对象检测、分类和分割来实现实时实例分割。
单词速度更快,两阶段精度更高。全景分割
全景风格模型既能确定所有像素的语义分类,又能区分图像中的每个对象实例,将语义分割和实例分割的优势结合在一起。目标侦测是找到图像中物体所在的大致位置,是回归问题目标分割是区分图像中哪些像素不属于目标物体,是一个像素级别的分类问题。
分割模型
分割模型为全卷积网络
自编解码结构:
- 编码器:将输入序列转换成一个固定长度向量
- 解码器:将生成的固定向量再转化成输出序列
上半为编码器 下半截为解码器 把特征向量还原成一幅图片
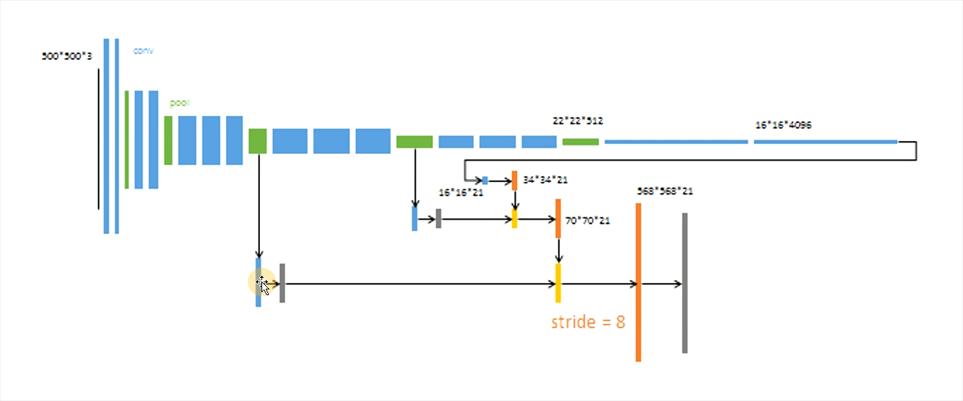
编解码结构
1 | import os.path |
卷积格式的自编码结构
1 |
转置卷积
空洞卷积
yolov8
基于检测框进行分割
1 | import cv2 |


