
优化器与损失函数
epoch和batch_size的选择
- epoch的作用在于逐步提高模型的精度,直到达到一个相对稳定的水平。
- batch size过小会导致模型训练过程不稳定,容易受到噪声数据干扰;而batch size过大则会导致模型训练时间过长。但batch size应该在设备允许的条件下尽可能的大,因为数量越多一个样本分布越接近真实值。
优化器optim
Adam和SGD通常是首选。Adam由于其自适应学习率特征,通常可以快速收敛,特别是在训练初期
SGD可能需要更细致的调优,但其优势在于训练后期可能会达到更好的性能。
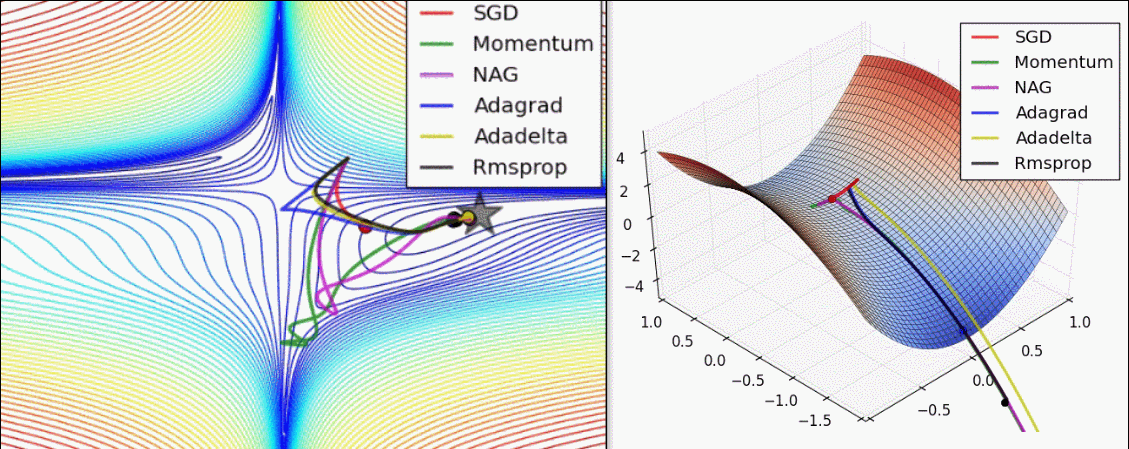
在解决cv问题时如何选择合适的优化器
小规模数据集和简单网络
A大grad,RMSprop也可能表现良好,这些优化器对每个参数的学习率进行自适应调整,有可能有助于更快的收敛
模型泛化
如果你关注模型的泛化能力,可能会考虑使用AdamW,他结合了Adam的自适应学习率和权重衰减,有助于防止过拟合
资源和效率
如果你的计算资源有限,或者需要快速迭代,可能会选择计算成本较低的优化器,如SGD和Adagrad
研究和比赛(不用在实践中)
在研究和比赛中,最佳实践是尝试多种优化器,并使用交叉验证来找到最佳配置。有时候,结合不同优化器的优点,如使用SGD进行预热,然后切换到Adam,也能带来提升
参考文献:随机梯度下降
三类梯度下降算法概述
GD(Gradient Descent):就是没有利用Batch Size,用基于整个数据库得到梯度,梯度准确,但数据量大时,计算非常耗时,同时神经网络常是非凸的,网络最终可能收敛到初始点附近的局部最优点。
SGD(Stochastic Gradient Descent):就是Batch Size = 1,每次计算一个样本,梯度不准确,所以学习率要降低。
mini-batch SGD:就是选择合适的Batch size算法,mini-batch利用噪声梯度,一定程度 上缓解了GD算法直接掉进初始点附近的局部最优解。同时梯度准确了,学习率要加大。
凸:
- 指的是顺着梯度方向走到底就 一定是 最优解 。
- 大部分 传统机器学习 问题 都是凸的。
非凸:
- 指的是顺着梯度方向走到底只能保证是局部最优,不能保证 是全局最优。
- 深度学习以及小部分传统机器学习问题都是非凸的。
最优化问题在机器学习中有非常重要的地位,很多机器学习算法都归结为求解最优化问题。在各种最优化算法中,梯度下降法是最简单、最常见的一种。
学习率衰减策略
- 固定步长衰减
- 多步长衰减
- 指数衰减
- 余弦退火
- (拿代码去做实验)
损失函数
网络训练时常用Loss为交叉熵(衡量两个概率分布之间的距离 概率分布 – 特征分布)
与mse的区别 sigmoid softmax
nn.crossentropyloss():多分类交叉熵 等效 torch.nn.logsoftmax()
nn.NLLLoss():多分类交叉熵
nn.BCELoss():二分类交叉熵 ~ nn.sigmoid() 输入在 0~1
log:简化计算 乘法变加法 提供稳定性 保证结果为正
nn.BCEWithLogLoss():this loss combines ‘sigmoid’ layer and the ‘BCELoss’ in one single
centerloss
- 减小类内距
1 | #中心点暂时无法确定,我们将中心点当成网络参数,让网络自己学习 |
arcsoftmax
- 增大类间距
1 | import torch |
特诊空间分类越好,分类效果越好


